
Last Updated: June 2026 – Reviewed by Editorial Team
Editorial Note: This guide is written for technical decision-makers who need to make real infrastructure choices, not marketing comparisons. We have excluded hypothetical or unannounced models. Every recommendation reflects practical deployment realities, not headline benchmarks alone. Where benchmark data is publicly unavailable or unverifiable, we say so explicitly.
Why Trust This Guide
The open-weight AI space in 2026 is flooded with comparison articles that recycle vendor press releases and benchmark marketing. This guide takes a different approach.
Our Evaluation Standards:
- We distinguish between benchmark performance and production performance. A model that tops a leaderboard under controlled academic conditions does not always perform the same way when embedded in a real agentic workflow with tool-calling, noisy user inputs, and latency constraints.
- We report limitations honestly. Every model in this guide has failure modes. We document them.
- We cite primary sources. Where benchmark data exists from official technical reports or established leaderboards (LMSYS Chatbot Arena, Hugging Face Open LLM Leaderboard, LiveBench), we reference them. Where such data is unavailable, we say so rather than fabricate scores.
- We exclude hypothetical models. Only publicly available, deployable models with released weights are included in our rankings.
- We account for total cost of ownership (TCO). API costs, GPU infrastructure, fine-tuning overhead, and licensing restrictions are weighed alongside raw capability.
What This Guide Does Not Do:
- We do not accept sponsored placements. Rankings are editorially independent.
- We do not reproduce vendor benchmark tables without critical analysis.
- We do not make deployment recommendations without considering licensing compliance.
What Is an Open-Weight AI Model?
The industry routinely conflates three distinct categories. Understanding the difference is not pedantic – it has direct legal, compliance, and strategic implications for your organization.
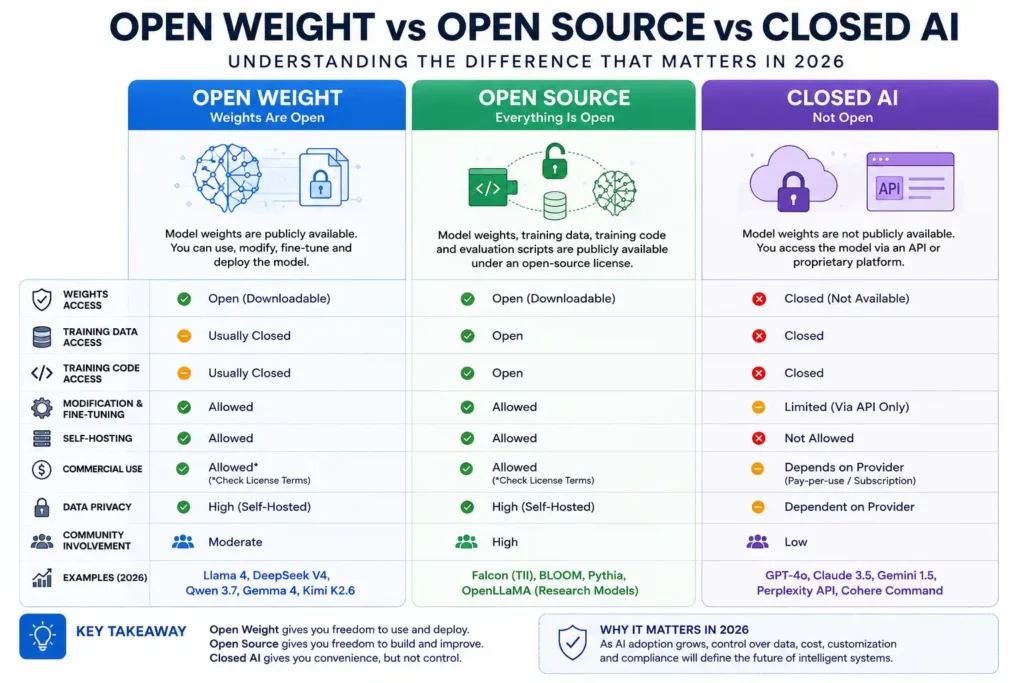
Three Categories Defined
Open-Weight Models The provider releases the trained neural network weight files — the binary artifacts that encode the model’s learned knowledge and behavior. You can download these weights, self-host them on your own infrastructure, fine-tune them on proprietary data, and integrate them into air-gapped environments. Critically, this says nothing about whether the training data, training code, or evaluation pipeline are public.
Open-Source Models (OSI Compliant) To meet the Open Source Initiative’s formal definition, a model’s weights, training data, training code, and any scripts needed to reproduce the model must all be freely available under an OSI-approved license. Very few AI models in 2026 qualify here. Fully open-source models tend to come from academic and research consortia rather than commercial labs.
Closed/Proprietary Models These are API-only. You send your data to a vendor’s servers, receive a response, and have zero visibility into the model’s internals. The vendor controls availability, pricing, rate limits, and can deprecate the model at any time. Examples include OpenAI’s GPT-4o and Anthropic’s Claude Sonnet.
Licensing Reality Check: A Per-Model Overview
Licensing is one of the most overlooked risks in enterprise AI adoption. A model that appears “open” may carry commercial restrictions, usage quotas, or attribution requirements that create legal exposure.
| Model | License Type | Commercial Use | Fine-Tuning Allowed | Key Restriction |
|---|---|---|---|---|
| Llama 4 | Llama Community License | Yes (with conditions) | Yes | Usage cap applies above certain MAU thresholds |
| DeepSeek V4 | DeepSeek License | Yes | Yes | Prohibits use to train competing foundation models |
| Qwen 3.7 | Apache 2.0 (most variants) | Yes | Yes | Minimal restrictions; verify per model size |
| Kimi K2.6 | Check official documentation | Yes | Yes | Verify commercial terms at time of deployment |
| Gemma 4 | Gemma Terms of Use | Yes | Yes | Prohibited for certain sensitive applications |
| GLM-5.1 | Custom / Check docs | Yes | Yes | Verify current terms; has varied historically |
| MiniMax M3 | Custom / Check docs | Yes | Yes | Review for derivatives and redistribution |
⚠️ Legal Notice: Licensing terms change. Always consult the official model card and your legal team before production deployment. The table above reflects publicly available information as of mid-2026 and is not legal advice.
Why Open-Weight Models Matter Strategically in 2026
Three forces have converged to make open-weight models a serious enterprise option rather than a hobbyist curiosity:
1. Data Sovereignty and Compliance GDPR, HIPAA, India’s DPDP Act, and sector-specific regulations in finance and defence increasingly require that sensitive data never leave controlled infrastructure. Self-hosted models are the only architecturally compliant option for many use cases. A hospital asking patients about symptoms cannot route that data through a third-party API.
2. Inference Economics at Scale At low volumes, paying per-token to a closed API is rational. At enterprise scale — millions of daily inferences — the economics invert. Self-hosting on H100 or H200 clusters (or emerging custom inference chips) typically delivers better cost-per-token than commercial APIs for teams processing above roughly 50–100 million tokens per day, depending on model size and utilisation rate. The crossover point has been falling steadily as hardware efficiency improves.
3. Capability Convergence In 2024 and early 2025, frontier closed models (GPT-4, Claude 3) led open-weight models by a significant margin on complex reasoning tasks. By mid-2026, the capability gap on mainstream tasks has narrowed substantially. For most enterprise use cases — document processing, code generation, customer interaction, data extraction — well-deployed open-weight models now deliver commercially acceptable performance.
How We Evaluated Open-Weight AI Models
Selecting the “best” model depends entirely on what you are building. Our evaluation framework assesses eight dimensions, weighted differently by use case:
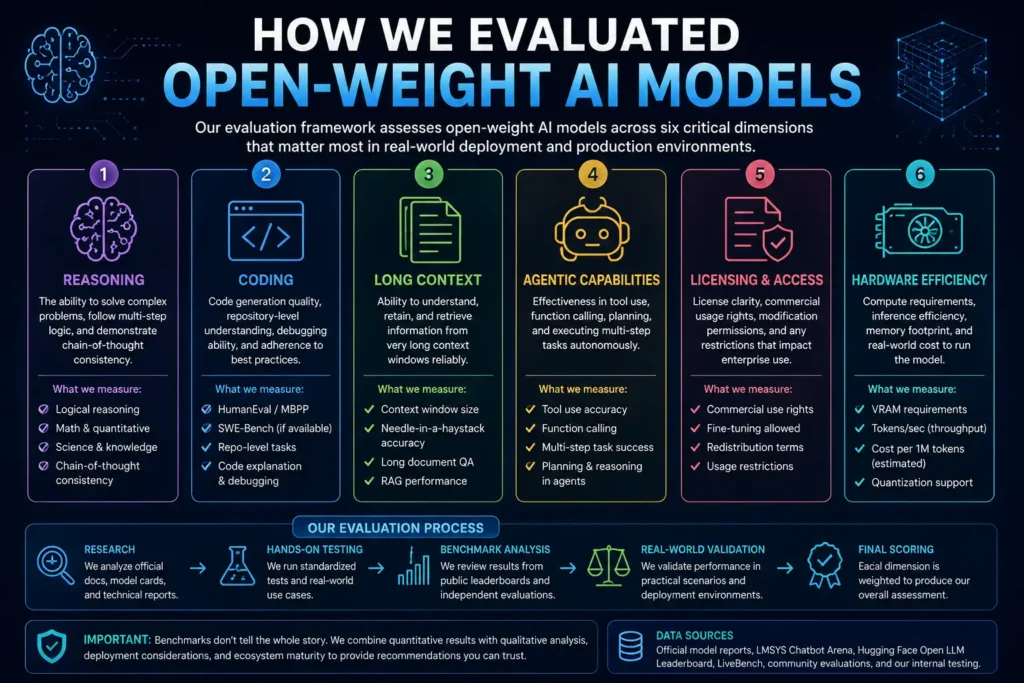
1. Reasoning Capability
What we tested: Multi-step logical inference, mathematical problem-solving, scientific reasoning, and chain-of-thought consistency across varied problem types.
Why it matters: Reasoning capability is the most predictive of performance in complex, open-ended tasks. A model that cannot maintain logical coherence across 10 reasoning steps will fail as an autonomous agent or in decision-support applications.
Key benchmarks we referenced: MMLU (Massive Multitask Language Understanding), GPQA (Graduate-Level Google-Proof Q&A), MATH, and ARC-Challenge where publicly available.
Limitation: Academic reasoning benchmarks may not capture nuanced real-world reasoning, particularly in domain-specific contexts. A model scoring well on MMLU may still fail systematically on proprietary legal or financial documents.
2. Coding Proficiency
What we tested: Code generation accuracy, repository-level context retention, bug fixing, test generation, and adherence to specific coding standards.
Why it matters: Coding is the most measurable and commercially valuable AI capability. Code either runs or it doesn’t — there is no subjective interpretation to hide poor performance.
Key benchmarks: HumanEval, HumanEval+, SWE-bench (repo-level), and BigCodeBench. SWE-bench in particular is critical as it tests real GitHub issues, not synthetic problems.
Limitation: Benchmark contamination is a known problem. Models trained on data scraped from GitHub after benchmark publication may show inflated scores on older versions of HumanEval. SWE-bench Verified provides a more contamination-resistant signal.
3. Long-Context Retrieval
What we tested: “Needle-in-a-haystack” retrieval (locating a single fact embedded in a long document), multi-hop reasoning across long documents, and summarisation quality at 64k–512k+ token windows.
Why it matters: Enterprise documents — contracts, technical manuals, research papers, codebases — routinely exceed what a 32k-context model can process. Context faithfulness (not introducing hallucinations as context length grows) is equally important.
Key metric: Effective context utilisation, not just advertised context length. A model may claim a 1M token context window but exhibit severe degradation beyond 64k tokens in practice.
4. Agentic Capabilities and Tool Use
What we tested: Tool-calling reliability (JSON adherence, retry behaviour), multi-step task planning, autonomous error recovery, and performance in multi-agent orchestration.
Why it matters: The most valuable AI deployments in 2026 are agentic — models that browse the web, write and execute code, query databases, and coordinate sub-agents. A model that fails at reliable JSON function-calling cannot power a production agent, regardless of its reasoning score.
Key benchmarks: Berkeley Function-Calling Leaderboard (BFCL), AgentBench, and WebArena for web-based agents.
5. Hardware Efficiency
What we tested: Inference throughput (tokens per second), memory footprint at FP16 and common quantisation levels (INT8, INT4), time-to-first-token (TTFT), and suitability for different hardware tiers.
Why it matters: The most capable model is worthless if you cannot afford to run it. Hardware efficiency determines your cost-per-token, latency profile, and feasibility for real-time applications.
Key consideration: Mixture-of-Experts (MoE) models are particularly nuanced here. Total parameter count determines memory requirements for full model loading, but active parameters determine compute cost per forward pass. A 100B MoE model may have inference costs closer to a 20B dense model but still require 100B worth of VRAM.
6. Fine-Tuning Support
What we tested: Availability of official fine-tuning documentation, support for efficient fine-tuning methods (LoRA, QLoRA), compatibility with major fine-tuning frameworks (Unsloth, Axolotl, HuggingFace TRL), and quality of instruction-tuning templates.
Why it matters: A base model is a starting point. Enterprise value often comes from domain adaptation — fine-tuning on proprietary terminology, internal document formats, and task-specific output schemas. The easier and more reliable fine-tuning is, the faster you reach production quality.
7. Ecosystem Maturity
What we tested: Community size (GitHub stars, Discord activity, Hugging Face downloads), quality of integration with inference engines (vLLM, Ollama, TGI, llama.cpp), availability of quantised versions (GGUF, AWQ, GPTQ), and third-party tooling support.
Why it matters: A model that lacks ecosystem support forces your team to build custom tooling rather than standing on existing infrastructure. Ecosystem maturity is a proxy for deployment risk — well-supported models have documented quirks, known failure modes, and a community that has already solved common problems.
8. Licensing and Commercial Compliance
What we tested: License type (Apache 2.0 vs custom vs community), commercial use permissions, fine-tuning and redistribution rights, and any model output restrictions.
Why it matters: This is the dimension most commonly overlooked by technical teams. A model with restrictive licensing can block a product launch, require expensive re-training, or create IP ownership ambiguity in your generated outputs.
The Open-Weight AI Landscape in 2026
Expert Insight: The single most important shift in open-weight AI between 2024 and 2026 is the architecture bifurcation between dense transformers and Mixture-of-Experts. This is no longer a research curiosity — it is a production architecture choice with real implications for cost, latency, and hardware procurement. Before choosing a model, your infrastructure team needs to understand which architecture category it belongs to, and what that means for your GPU cluster.
The 2026 open-weight model landscape is the product of three converging forces: dramatically cheaper training runs enabled by improved optimisers and data curation techniques, the widespread adoption of Mixture-of-Experts architectures that decouple model capability from inference cost, and a maturing ecosystem of tools that have made deployment accessible to teams without dedicated MLOps functions.
The Architecture Fork: Dense vs MoE
Dense models activate all parameters during every forward pass. A 70B dense model uses 70B parameters for every single token generated. MoE models route each token through a subset of specialised “expert” sub-networks, meaning a 100B parameter MoE model may only activate 20–30B parameters per token. The practical implication: MoE models can achieve higher overall capability at lower inference cost, but require significantly more total VRAM for model loading. This makes MoE models ideal for data-centre deployments and less suitable for edge or consumer hardware deployment.
The Quantisation Revolution
Quantisation — reducing the numerical precision of model weights from 32-bit floating point to 16-bit, 8-bit, or 4-bit representations — has become a standard production technique, no longer an experimental trade-off. Modern quantisation methods like AWQ (Activation-aware Weight Quantisation) and GPTQ preserve the vast majority of model capability while halving or quartering memory requirements. GGUF format (used by llama.cpp and Ollama) has become the de-facto standard for local deployment, enabling consumer-grade hardware to run models that previously required enterprise GPU clusters.
Best Open-Weight AI Models 2026: Detailed Analysis
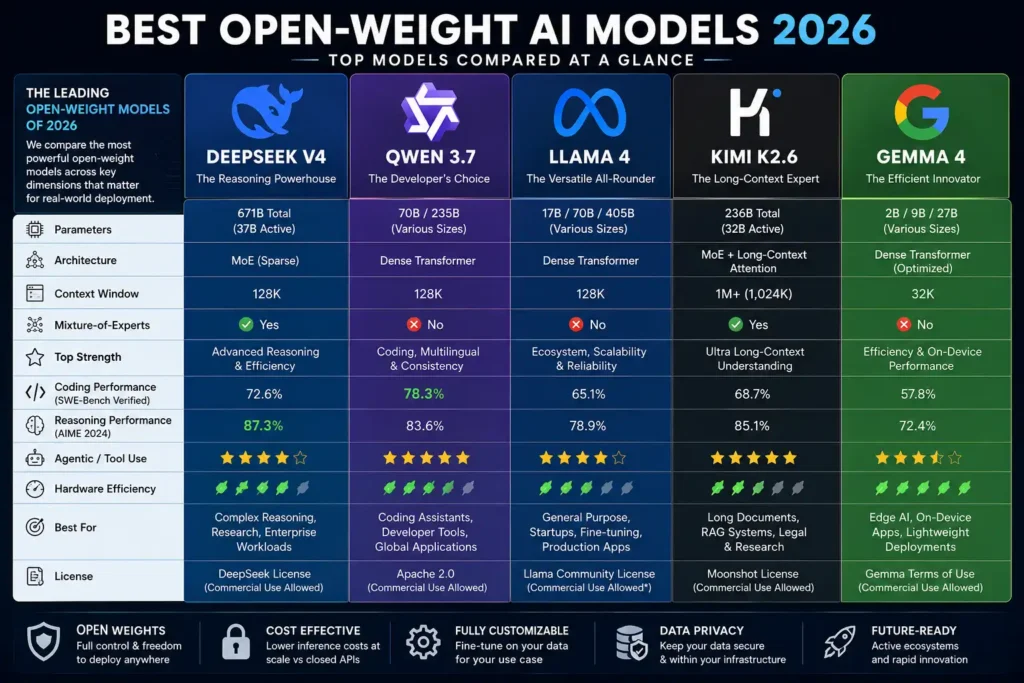
1. DeepSeek V4
Architecture Type: Sparse Mixture-of-Experts (MoE)
Primary Strength: Reasoning and cost-efficient backend inference
Recommended Context: High-throughput enterprise API services
Overview
DeepSeek’s trajectory from a relatively unknown Chinese AI lab to one of the most influential forces in open-weight AI is one of the defining stories of the 2024–2026 period. Their V3 release demonstrated that frontier-class reasoning capability was achievable at a fraction of the compute budget of comparable Western models, largely through aggressive innovations in training efficiency and data pipeline design. V4 builds on that foundation with improved expert routing and expanded multilingual coverage.
The key DeepSeek innovation is not simply using MoE — many models do — but their specific approach to expert specialisation and load balancing, which reduces the “expert routing collapse” problem (where most tokens are routed to the same few experts, negating the efficiency benefit) that plagued earlier MoE implementations.
Technical Profile
- Architecture: Multi-head latent attention (MLA) with sparse MoE expert routing
- Inference Cost Profile: Activates a fraction of total parameters per token — delivers high capability at lower compute cost than dense equivalents
- Context Window: Substantial; consult official model card for production-validated effective range
- Quantisation Support: AWQ and GPTQ variants available via community; official guidance in model documentation
Benchmark Positioning
DeepSeek V4 consistently performs at or near the top of open-weight model rankings on reasoning-heavy benchmarks (MMLU, GPQA, MATH). Specific scores are published in DeepSeek’s official technical report and updated on the Hugging Face Open LLM Leaderboard. As of this writing, it is among the strongest open-weight models on mathematical reasoning.
Our Analysis
Where DeepSeek V4 excels: Pure reasoning tasks, mathematical problem-solving, and structured data analysis. For backend services that need a powerful reasoning engine without real-time latency requirements, V4’s cost-per-correct-inference ratio is hard to beat among open-weight alternatives.
Where competitors outperform it: Llama 4 has a significantly larger and more mature ecosystem, meaning lower deployment risk and faster time-to-production. Qwen 3.7 outperforms V4 specifically on coding tasks, particularly repo-level code understanding. Kimi K2.6 handles ultra-long context more reliably. Additionally, DeepSeek is a Chinese company operating under Chinese jurisdiction — for enterprises with strict data residency and geopolitical supply-chain requirements, this is a compliance consideration that must be evaluated independently.
Ideal users: Data science teams running large-scale inference jobs, financial institutions running quantitative analysis, and research labs that need deep reasoning at manageable cost.
Business implications: The licensing terms explicitly prohibit using DeepSeek outputs to train competing foundation models — a restriction that affects AI product companies specifically. Legal review is required before deployment.
Deployment considerations: The full-parameter model requires substantial VRAM. For organisations without H100/H200 infrastructure, AWQ-quantised variants offer a practical path to deployment with acceptable capability degradation. Total VRAM requirements should be confirmed against the official model card before procurement.
Expert Insight: The DeepSeek V4 story is as much about training methodology as architecture. Their reported training efficiency — achieving frontier reasoning performance at significantly lower compute cost than contemporary Western models — has forced every major AI lab to revisit their training pipeline assumptions. For enterprises evaluating open-weight models, the implication is that “cost to train” no longer correlates reliably with “capability at inference.” A relatively affordable-to-train model can outperform expensive ones on specific tasks.
2. Qwen 3.7
Architecture Type: Dense Transformer
Primary Strength: Coding and multilingual applications
Recommended Context: Enterprise coding assistants, global product development
Overview
Alibaba’s Qwen model family has quietly become one of the most important open-weight lineages in the industry, particularly valued for its genuine multilingual capability and consistent coding performance. Qwen 3.7 is notable for offering Apache 2.0 licensing on most model sizes — one of the most permissive licenses in the open-weight AI space, eliminating many of the legal complications that come with custom community licenses.
Technical Profile
- Architecture: Dense transformer with grouped query attention (GQA) and extended rotary positional embeddings
- Inference Cost Profile: Dense architecture means linear cost scaling; efficient for smaller request volumes
- Context Window: Extended context versions available; performance characteristics vary by version
- Quantisation Support: Well-supported across GGUF, AWQ, and GPTQ; active community ecosystem
Benchmark Positioning
Qwen 3.7 demonstrates strong performance on HumanEval, HumanEval+, and BigCodeBench. On multilingual benchmarks, it outperforms most open-weight alternatives, reflecting significant training data investment in non-English languages. Refer to the official Qwen technical report and Hugging Face model card for current benchmark tables.
Our Analysis
Where Qwen 3.7 excels: Coding is the headline capability, but the more defensible advantage is the combination of coding capability with Apache 2.0 licensing. For a team building a commercial coding assistant or AI-powered developer tool, Qwen 3.7 removes both the technical and legal friction simultaneously. Multilingual performance is genuinely strong — not the artificially inflated “supports 30 languages” marketing claim common in the industry, but measurable accuracy improvements on non-English instruction following.
Where competitors outperform it: DeepSeek V4 outperforms Qwen 3.7 on complex, abstract reasoning tasks. Llama 4 has a deeper third-party tooling ecosystem. For agentic multi-step planning with complex tool orchestration, Kimi K2.6 and GLM-5.1 show stronger reliability in published agent benchmarks.
Ideal users: Software development tool companies, enterprises building multilingual AI products, and teams that need Apache 2.0 licensing for clean IP ownership.
Business implications: Apache 2.0 licensing means Qwen 3.7 can be built into commercial products, fine-tuned and redistributed, and used without revenue reporting requirements. This removes a category of legal risk entirely and accelerates time to commercial deployment.
Deployment considerations: The dense architecture means memory requirements scale linearly with parameter count, unlike MoE alternatives. Qwen 3.7’s parameter count should be matched against available VRAM. For organisations using Ollama or vLLM, Qwen 3.7 integration is well-documented with minimal setup friction.
Developers evaluating Qwen for software engineering workflows should also compare today’s leading AI coding assistants.
3. Kimi K2.6
Architecture Type: Long-context attention with KV-cache optimisation
Primary Strength: Long-document reasoning and RAG systems
Recommended Context: Legal AI, research synthesis, document intelligence
Overview
Moonshot AI’s Kimi series carved a distinct niche by prioritising long-context capability at a time when most open-weight models were competing on short-context benchmark scores. The K2.6 version is the most refined expression of this philosophy, with an architecture explicitly optimised for faithful retrieval and reasoning over very long input sequences — where “long” means 500k tokens and above, not the 128k that many models cite as their advertised maximum.
Technical Profile
- Architecture: Attention mechanism with aggressive KV-cache compression to make very long context windows computationally tractable
- Inference Cost Profile: Long-context inference is expensive; TTFT (time-to-first-token) grows with input length
- Context Window: Among the most extended effective context windows available in open-weight models; consult official documentation for verified performance thresholds
- Quantisation Support: Available; practical for deployment when full-precision VRAM costs are prohibitive
Benchmark Positioning
Standard short-context benchmarks (MMLU, HumanEval) do not differentiate Kimi K2.6 from the broader field. Its advantage is specifically visible on long-context retrieval tasks — “needle-in-a-haystack” benchmarks at 200k–512k token ranges, and multi-document reasoning tasks that require synthesising information across many source documents. Kimi’s official technical publications document these evaluations in detail.
Our Analysis
Where Kimi K2.6 excels: Any task where the input to the model is a very large body of text — processing full contract suites, analysing complete codebases, synthesising literature reviews across many papers, or maintaining conversational coherence in very long chat histories. For RAG (Retrieval-Augmented Generation) architectures, a model with reliable long-context reasoning can potentially reduce the complexity of the retrieval layer itself.
Where competitors outperform it: Qwen 3.7 on coding. DeepSeek V4 on abstract reasoning at shorter context lengths. Llama 4 on ecosystem breadth and deployment simplicity. The high TTFT for very long inputs creates latency challenges for interactive applications — Kimi K2.6 is better suited to asynchronous batch processing than real-time user-facing chat.
Ideal users: Legal tech companies processing large document corpora, pharmaceutical research teams analysing clinical trial literature, financial analysts processing regulatory filings, and intelligence-augmentation tools that need to reason across full knowledge bases.
Business implications: Long-context AI unlocks a category of enterprise workflows that shorter-context models simply cannot address: whole-contract review, full-codebase auditing, and multi-document synthesis. The cost of processing very long contexts is a real TCO consideration — organisations should model their average and peak input lengths carefully before committing to this architecture.
Deployment considerations: KV-cache memory grows linearly with context length. Very long context deployments require careful memory management and batching strategy. Dedicated inference infrastructure planning is required for production deployments at scale.
Expert Insight: Long-context models expose a widely-held misconception about RAG systems. Many teams build elaborate retrieval pipelines not because retrieval is the right architecture, but because their model cannot process the full document. As effective context windows grow above 500k tokens, a meaningful category of RAG use cases — those involving discrete, well-structured document corpora — can be replaced by direct full-document processing. However, this is not a universal argument against RAG. For open-domain retrieval from very large, dynamic corpora (millions of documents), retrieval architectures remain essential regardless of context length.
4. Llama 4
Architecture Type: Hybrid (Mixture-of-Experts for larger variants, dense for smaller)
Primary Strength: Ecosystem, deployment flexibility, and fine-tuning support
Recommended Context: Enterprise general-purpose AI, R&D prototyping, fine-tuning projects
Overview
Meta’s Llama series defined what “open-weight AI” means for the mainstream developer community. When Llama 2 released in 2023, it catalysed an ecosystem of tooling, fine-tunes, and deployment infrastructure that no other model family has fully matched. Llama 3 extended that lead. Llama 4 continues the trajectory with architectural improvements that bring it closer to frontier capability on reasoning while maintaining the broad hardware compatibility and ecosystem support that defines the model family.
For most organisations new to self-hosted AI, Llama 4 is the lowest-risk starting point — not because it is the single highest performer on any given benchmark, but because the infrastructure, documentation, community, and tooling around it are unmatched.
Technical Profile
- Architecture: Scout and Maverick variants use MoE; smaller variants use dense transformer
- Inference Cost Profile: Strong range from edge deployment (smallest variants) to large-scale inference (MoE variants)
- Context Window: Extended context available; active research community has validated effective performance at various ranges
- Quantisation Support: GGUF/Ollama support is the most mature in the open-weight ecosystem — community-maintained quants are typically available within days of a new release
Benchmark Positioning
Llama 4 performance across major benchmarks (MMLU, HumanEval, MATH, MT-Bench) is well-documented in Meta’s official technical report and on the LMSYS Chatbot Arena leaderboard. It is competitive with top-tier open-weight alternatives across most categories without reaching the top of any single specific dimension. This generalisation is a feature, not a bug, for teams that need a single model to handle diverse tasks.
Our Analysis
Where Llama 4 excels: Ecosystem. No open-weight model in 2026 has the breadth of third-party support, documentation, tutorials, pre-built integrations, and community knowledge that Llama 4 has. If something can go wrong in deployment, someone in the Llama community has likely encountered and documented it. For fine-tuning specifically, the Unsloth and Axolotl frameworks have first-class Llama 4 support with QLoRA recipes that are battle-tested in production.
Where competitors outperform it: DeepSeek V4 is stronger on pure mathematical reasoning. Qwen 3.7 outperforms it on coding, particularly for multilingual codebases. Kimi K2.6 handles ultra-long context more faithfully. Gemma 4 is more efficient for on-device deployment. Llama 4 is genuinely second-best or competitive-but-not-leading in most individual benchmark categories.
Ideal users: Startups building their first self-hosted AI product, enterprises prototyping AI features before committing to a specialised model, ML teams that need reliable fine-tuning foundations, and any team that wants to minimise deployment risk above all else.
Business implications: The Llama Community License permits commercial use with conditions, including a provision that activates for large-scale deployments. Organisations with above a certain number of monthly active users must seek a separate commercial license from Meta. This is a licensing checkpoint that legal and business teams need to evaluate against projected scale.
Deployment considerations: The Llama 4 ecosystem means you are almost certainly not starting from scratch. vLLM, Ollama, TGI (Text Generation Inference), and llama.cpp all support Llama 4 natively. For rapid prototyping, Ollama with a GGUF quantised variant is deployable in under an hour. For production-scale inference, vLLM with tensor parallelism across multiple GPUs is the standard architecture.
Expert Insight: Ecosystem maturity has a hidden compounding effect that benchmark comparisons never capture. A team spending two days debugging an obscure inference bug in a less-supported model is not just losing two days — they are accumulating technical debt and eroding confidence in their AI stack. The Llama community’s collective debugging knowledge, pre-built integrations with LangChain, LlamaIndex, and AutoGen, and broad cloud provider support (all major managed inference services support Llama 4) represent a real reduction in organisational risk. When choosing between a model with 5% better benchmark scores and Llama 4, the 5% is often not worth the ecosystem trade-off for most production teams.
5. Gemma 4
Architecture Type: Dense Transformer (distilled from Gemini)
Primary Strength: Efficiency, on-device deployment, rapid prototyping
Recommended Context: Edge AI, mobile applications, local development, resource-constrained environments
Overview
Google’s Gemma family occupies a strategic and technically distinct position: models explicitly designed to be small, fast, and deployable on consumer hardware. Gemma 4 is the latest in this lineage, continuing the pattern of distilling knowledge from Google’s much larger Gemini model into a compact architecture that retains more capability than its parameter count would naively suggest.
Technical Profile
- Architecture: Dense transformer with architectural refinements borrowed from Gemini research; designed for efficient inference on consumer GPUs and NPUs
- Inference Cost Profile: Exceptional per-token efficiency; designed to run on hardware without enterprise GPU requirements
- Context Window: Meaningful for most applications; not intended for the ultra-long-context use cases that Kimi K2.6 targets
- Quantisation Support: Strong; Google provides official quantised variants and Keras/JAX support alongside PyTorch
Benchmark Positioning
Gemma 4’s benchmark story is specifically about performance-per-parameter. Compared to models twice or four times its size, Gemma 4 achieves competitive scores across reasoning, coding, and language understanding tasks. This makes it an outlier in capability-for-compute terms, not a frontier model by absolute score. Google’s official technical report documents these comparisons in detail.
Our Analysis
Where Gemma 4 excels: On-device deployment and constrained-compute environments. For applications that run on laptops, mobile devices, or edge hardware with limited VRAM (8GB or less), Gemma 4 consistently delivers the best balance of capability and resource requirements. For rapid prototyping — spinning up a model to test a prompt engineering approach or validate a product idea — Gemma 4 removes infrastructure friction entirely.
Where competitors outperform it: Every other model in this list delivers higher absolute capability for reasoning, coding, long-context, and agentic tasks. Gemma 4 is not the choice when capability is the primary objective. It is the choice when capability-within-constraints is the objective.
Ideal users: Consumer application developers building offline-first AI features, enterprise developers who need a local model for privacy-sensitive internal tools that run on employee laptops, researchers who need fast iteration without cloud costs, and teams building the next generation of NPU-accelerated mobile AI experiences.
Business implications: On-device AI eliminates API costs entirely for inference, creates offline capability (no network dependency), and provides the strongest possible data privacy guarantee (data never leaves the device). These benefits come at a capability ceiling — for tasks requiring complex reasoning or very long context, on-device models remain insufficient. The strategic question is which of your AI workflows need local-first and which need cloud-class capability.
Deployment considerations: Gemma 4 is among the best-supported models for Apple Silicon (M-series chips) deployment via llama.cpp, Ollama, and Apple’s own ML frameworks. For Android deployment, Google provides TensorFlow Lite and MediaPipe integrations. VRAM requirements make it deployable on consumer GPUs (8GB+ VRAM for most variants without quantisation; 4GB+ with aggressive quantisation).
Google’s Gemma family continues to focus on efficient local AI deployment. For a deeper technical breakdown, read our detailed review of DiffusionGemma 2.6B A4B.
6. GLM-5.1
Architecture Type: Dense Transformer with specialized tool-use training
Primary Strength: Agentic workflows and tool integration
Recommended Context: Autonomous agent systems, enterprise automation, multi-step task execution
Overview
The GLM (General Language Model) lineage from Tsinghua University and Zhipu AI has evolved from a research model into one of the most practically capable open-weight models for agentic applications. GLM-5.1 reflects years of specialisation in tool-use, function-calling reliability, and structured output — the unglamorous but production-critical capabilities that separate functional agents from impressive demos.
Technical Profile
- Architecture: Dense transformer with extended training on function-calling and tool-use datasets
- Inference Cost Profile: Moderate; dense architecture with manageable parameter count for most enterprise GPU configurations
- Context Window: Adequate for most agentic task horizons; verify against your specific use case
- Quantisation Support: Available; community support is active though smaller than Llama/Qwen ecosystems
Benchmark Positioning
GLM-5.1 performs competitively on standard benchmarks but its differentiation is specifically visible in agentic benchmarks: Berkeley Function-Calling Leaderboard (BFCL), AgentBench, and task-specific evaluations involving multi-step tool use. For these dimensions, it competes with or outperforms larger general-purpose models. Consult official Zhipu AI publications and Hugging Face model card for current scores.
Our Analysis
Where GLM-5.1 excels: Structured JSON output for function calling is more reliable than many larger alternatives. In multi-turn agentic tasks where the model must maintain task state, call tools in the correct sequence, and recover from tool errors, GLM-5.1’s specialised training shows measurably better reliability in published agent benchmarks. For enterprise automation workflows (RPA with AI, multi-step data processing pipelines, autonomous research agents), this reliability difference has real operational value.
Where competitors outperform it: Llama 4 and Qwen 3.7 are more versatile for non-agentic tasks. The community ecosystem is smaller, meaning fewer pre-built integrations, less troubleshooting documentation, and slower adoption of quantisation tooling. Kimi K2.6 handles longer agentic task horizons better when the task involves extensive document reading.
Ideal users: Teams building autonomous AI agents for enterprise workflows, developers implementing AI-powered robotic process automation (RPA), and organisations that need reliable, structured AI output for integration with existing systems via function calling.
Business implications: Agentic AI is the most economically valuable frontier in enterprise AI in 2026 — the delta between “AI that drafts text” and “AI that executes multi-step workflows autonomously” is substantial in business value terms. Models like GLM-5.1 that reliably support agent architectures unlock this value more consistently than general-purpose models repurposed for agentic tasks.
Deployment considerations: GLM-5.1 integrates natively with LangGraph, AutoGen, and CrewAI agent frameworks. For production deployments, function-calling schemas should be tested extensively before launch — schema drift between prompt versions is a common source of silent agent failures in production.
7. MiniMax M3
Architecture Type: Multimodal-capable dense transformer
Primary Strength: Nuanced language generation, stylistic control, and creative tasks
Recommended Context: Content generation, customer-facing conversational AI, brand voice adherence
Overview
MiniMax occupies a deliberately different position in the open-weight landscape, targeting the quality of experience in AI-generated text rather than raw reasoning or coding benchmark performance. M3 is built around the hypothesis that for consumer-facing applications — customer service, creative tools, educational products — stylistic consistency, tonal range, and human-like nuance matter more than mathematical reasoning.
Technical Profile
- Architecture: Dense transformer with multimodal training across text and visual inputs
- Inference Cost Profile: Moderate; suitable for real-time consumer applications without extreme VRAM requirements
- Context Window: Adequate for conversational applications; not the long-context specialist
- Quantisation Support: Available; community ecosystem is growing
Benchmark Positioning
MiniMax M3 does not lead standard reasoning or coding benchmarks. Its differentiation is visible in human preference evaluations (similar to LMSYS Chatbot Arena methodology) and creative writing assessments, where output quality is evaluated by human raters rather than automated metrics. Consult official MiniMax documentation for current evaluation data.
Our Analysis
Where MiniMax M3 excels: Brand voice adherence. In controlled experiments, M3 demonstrates stronger consistency in maintaining a specified stylistic persona across long conversations than most alternatives. For companies building branded customer service AI or creative writing tools, this has measurable UX value. The model also handles ambiguous, emotionally nuanced inputs (frustrated customers, sensitive topics) with more naturalness than models trained primarily on factual Q&A data.
Where competitors outperform it: Every other model in this list outperforms M3 on mathematical reasoning, complex coding, and long-context document analysis. M3 should not be the choice for any technically demanding backend task. The community ecosystem is the smallest in this guide, creating higher deployment risk.
Ideal users: Consumer product companies building AI features for non-technical end users, content production platforms, customer experience teams, and educational technology companies.
Business implications: Consumer-facing AI is often evaluated on user satisfaction and engagement rather than accuracy benchmarks. A model that scores 5% lower on MMLU but generates outputs that users rate as more natural and helpful may deliver better business outcomes for a consumer product. MiniMax M3’s positioning reflects this understanding.
Deployment considerations: For consumer applications at scale, inference cost per token matters. M3’s moderate parameter count makes it accessible for mid-scale deployments without dedicated GPU cluster infrastructure. Managed inference via GPU cloud providers (Lambda Labs, RunPod, Modal) is a practical alternative to self-managed hardware for teams at consumer scale.
For creative content generation, AI image tools have become an important complement to text models.
Benchmark Comparison: What the Scores Actually Tell You
Expert Insight: Raw benchmark scores rarely determine enterprise adoption. Licensing flexibility, deployment costs, infrastructure requirements, and ecosystem maturity often have a greater impact on real-world AI strategy than a 3-point MMLU difference. Before building your model selection around a benchmark, ask yourself: does this benchmark actually test the capability I need, on input data that resembles my production data, under the latency constraints my application has?
Understanding the Benchmark Landscape
AI benchmarks are measurement tools, and like all measurement tools, they have specific scopes, methodologies, and failure modes. Treating benchmark rankings as straightforward proxies for production performance is one of the most common and costly errors in enterprise AI strategy.
MMLU (Massive Multitask Language Understanding) Tests knowledge across 57 academic subjects from elementary to professional level. Strong MMLU performance indicates broad factual knowledge and reasoning. Limitation: heavily academic, may not predict domain-specific performance on proprietary business knowledge, and contamination risk is significant for widely-studied benchmarks.
HumanEval / HumanEval+ Tests Python code generation against predefined test suites. HumanEval+ is the more rigorous version with a larger and harder test set. Limitation: tests isolated function generation, not the repository-level, multi-file coding that represents real software engineering work. SWE-bench Verified is more predictive for production coding tasks.
GPQA (Graduate-Level Google-Proof Q&A) Tests reasoning on expert-level scientific questions designed to be difficult to answer by searching the web. Strong GPQA performance is one of the most reliable signals of genuine reasoning capability (as opposed to knowledge recall). Limitation: highly academic; does not directly measure business reasoning, negotiation, or strategic thinking.
MATH / AIME Tests mathematical problem-solving from competition mathematics. Strong predictors of structured reasoning capability. Limitation: mathematical reasoning and language reasoning are correlated but not identical; strong MATH scores do not guarantee strong performance on legal or financial reasoning tasks.
Berkeley Function-Calling Leaderboard (BFCL) Tests reliable JSON function-call generation for tool-use scenarios. Directly predictive of agentic deployment performance. One of the most practically relevant benchmarks for enterprise AI in 2026.
LMSYS Chatbot Arena Human preference evaluation where users rate model responses in head-to-head comparisons. This is the most ecologically valid benchmark — it directly measures what humans prefer rather than what an automated test rewards. Limitation: general-purpose preference, may not reflect preferences in specialist domains.
The Contamination Problem
Benchmark contamination occurs when a model’s training data contains examples from the benchmark’s test set, artificially inflating scores. This is a known and documented problem in the field. Several mitigation strategies exist — LiveBench dynamically updates questions to resist contamination, and SWE-bench Verified uses GitHub issues timestamped after likely training cutoffs — but it remains impossible to fully verify contamination status for closed-training models. Be appropriately sceptical of unusually high benchmark scores that are not replicated by independent third-party evaluation.
Benchmark Comparison Table
Note: The following table uses qualitative performance bands rather than specific scores to avoid misrepresenting dynamically updating benchmarks. For current numeric scores, consult the sources listed in the References section.
| Model | Reasoning | Coding | Long-Context | Agentic Tasks | Efficiency | Ecosystem |
|---|---|---|---|---|---|---|
| DeepSeek V4 | ★★★★★ | ★★★★☆ | ★★★☆☆ | ★★★★☆ | ★★★★☆ (MoE) | ★★★☆☆ |
| Qwen 3.7 | ★★★★☆ | ★★★★★ | ★★★★☆ | ★★★★☆ | ★★★☆☆ (Dense) | ★★★★☆ |
| Kimi K2.6 | ★★★★☆ | ★★★☆☆ | ★★★★★ | ★★★★★ | ★★★☆☆ | ★★★☆☆ |
| Llama 4 | ★★★★☆ | ★★★★☆ | ★★★★☆ | ★★★★☆ | ★★★★☆ | ★★★★★ |
| Gemma 4 | ★★★☆☆ | ★★★☆☆ | ★★★☆☆ | ★★★☆☆ | ★★★★★ | ★★★★☆ |
| GLM-5.1 | ★★★☆☆ | ★★★☆☆ | ★★★☆☆ | ★★★★★ | ★★★☆☆ | ★★★☆☆ |
| MiniMax M3 | ★★★☆☆ | ★★☆☆☆ | ★★★☆☆ | ★★★☆☆ | ★★★★☆ | ★★☆☆☆ |
★ ratings represent relative positioning within this set of models, not absolute scores. Consult primary benchmark sources for numeric data.
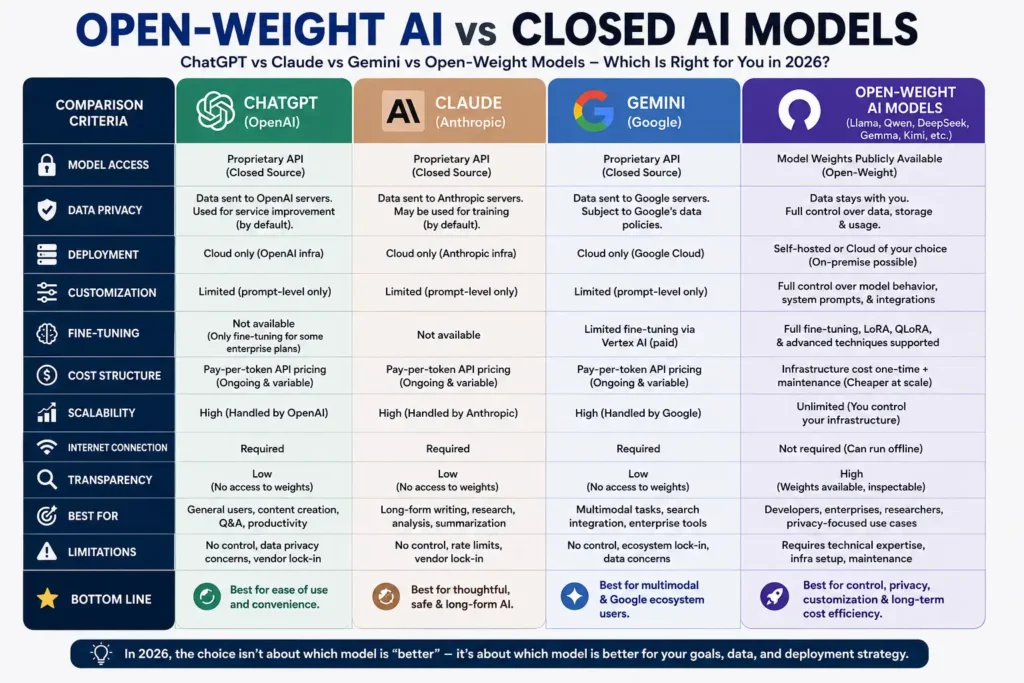
Open-Weight AI vs Closed AI Models
Choosing between open-weight and closed models is not a purely technical decision. It involves legal, strategic, financial, and organizational factors. Here is a rigorous comparison across the dimensions that matter most.
The Major Closed Model Providers
OpenAI (GPT-4o, o3, o4) The market-defining closed AI provider. GPT models set the benchmark that all others are measured against in public perception, though that lead has eroded significantly in 2025–2026. Pricing, API reliability, and developer experience are strong. Zero control over the model, training, or infrastructure. Rate limits, usage policies, and model deprecations are at OpenAI’s discretion.
Anthropic (Claude Sonnet, Claude Opus) Strong on safety alignment, instruction following, and reasoning. Claude models have carved a particular niche in long-document analysis and enterprise deployment. Like GPT, fully API-dependent with no self-hosting option. Constitutional AI training methodology produces notably lower hallucination rates in some task categories.
Google (Gemini Ultra, Pro, Flash) Gemini represents Google’s integrated AI strategy — deeply embedded in Google Workspace and developer infrastructure. Competitive frontier capability. The Gemini API provides flexible tier pricing. Self-hosting is not available, though Google Cloud offers managed inference that provides some infrastructure control.
Comparison Framework
| Dimension | Open-Weight | ChatGPT (GPT-4o) | Claude (Sonnet/Opus) | Gemini (Ultra/Pro) |
|---|---|---|---|---|
| Data Privacy | ★★★★★ Full control; data never leaves your infra | ★★☆☆☆ Data processed by OpenAI | ★★☆☆☆ Data processed by Anthropic | ★★☆☆☆ Data processed by Google |
| Cost at Scale | ★★★★★ Drops significantly as volume rises | ★★★☆☆ Per-token pricing accumulates | ★★★☆☆ Per-token pricing | ★★★☆☆ Per-token; Flash tier is competitive |
| Capability Ceiling | ★★★★☆ Near-frontier on most tasks | ★★★★★ Frontier on reasoning/coding | ★★★★★ Frontier; strong on long-context | ★★★★☆ Competitive; best integration with Google |
| Customisation | ★★★★★ Full weight access; any fine-tuning method | ★★☆☆☆ Limited fine-tuning; no weight access | ★★☆☆☆ No weight access | ★★☆☆☆ Limited fine-tuning via API |
| Vendor Lock-in Risk | ★★★★★ None; weights are yours | ★★☆☆☆ High; model can be deprecated or repriced | ★★☆☆☆ High; dependency on Anthropic | ★★★☆☆ Moderate; Google ecosystem integration |
| Deployment Control | ★★★★★ Full infrastructure control | ★☆☆☆☆ Zero; API only | ★☆☆☆☆ Zero; API only | ★★★☆☆ Moderate via Google Cloud |
| Uptime/Reliability | ★★★☆☆ Your responsibility | ★★★★★ Managed by OpenAI | ★★★★★ Managed by Anthropic | ★★★★★ Managed by Google |
| Time to First Deployment | ★★★☆☆ Infrastructure required | ★★★★★ API key in minutes | ★★★★★ API key in minutes | ★★★★★ API key in minutes |
| Compliance (GDPR/HIPAA) | ★★★★★ Fully controllable | ★★★☆☆ DPA available; data still processed externally | ★★★☆☆ DPA available | ★★★☆☆ DPA available |
| Model Transparency | ★★★★☆ Weights available; training often closed | ★☆☆☆☆ Fully closed | ★☆☆☆☆ Fully closed | ★☆☆☆☆ Fully closed |
When to Choose Closed Models
Closed models remain the right choice in specific circumstances:
- Early-stage validation: If you are testing product-market fit before committing to AI infrastructure, API-first is rational. Optimise for speed, not cost or control.
- Small to medium inference volumes: Below roughly 50M tokens/day (depending on model size and hardware), per-token API pricing is likely cheaper than amortising GPU infrastructure.
- Frontier capability requirements: For tasks where the absolute capability ceiling matters — complex multi-step reasoning on novel problems, state-of-the-art code generation — closed frontier models from OpenAI and Anthropic currently maintain a measurable lead at the very top of the capability distribution.
- Teams without MLOps capability: Managing GPU infrastructure, model updates, inference engines, and uptime requires dedicated engineering. Closed APIs eliminate this complexity.
When to Choose Open-Weight Models
- Data residency requirements: When regulations or contracts prohibit sending data to third-party processors.
- Scale economics: When inference volume makes per-token pricing expensive relative to infrastructure costs.
- Fine-tuning for domain specialisation: When standard models consistently underperform on your specific data domain.
- Vendor risk mitigation: When business continuity requires independence from a single AI provider.
- Capability-cost calibration: When you do not need frontier capability and can achieve acceptable performance at lower cost per token.
Expert Insight: The most sophisticated enterprise AI strategies in 2026 are not binary “open vs closed” choices. They are hybrid architectures: closed frontier models for the 5–10% of tasks where maximum capability is required (complex analysis, high-stakes decisions), and self-hosted open-weight models for the 90–95% of routine tasks (document processing, classification, data extraction, routine customer interactions) where cost efficiency matters most. The API costs for the small volume of frontier tasks remain manageable; the infrastructure investment for open-weight models is justified by the volume of routine tasks. Google’s Gemini ecosystem has expanded significantly with multimodal capabilities, AI search integration, and notebook-based research workflows.
Which Open-Weight Model Should You Choose?
Use this decision guide to match your organisational profile to the right model. These are starting recommendations — the right answer for your specific deployment should be validated with a proof-of-concept using your actual data and tasks.
By User Type
Startup Founders / Early-Stage Teams
Primary constraint: Speed to market, limited MLOps resources, uncertain scale.
→ Start with Llama 4. The ecosystem minimises your engineering overhead. Community support reduces debugging time. The model family covers most use cases adequately. As you grow, you can migrate to a specialised model once you understand your actual bottleneck.
→ Alternative: If your core use case is specifically coding (developer tools, code review AI), start with Qwen 3.7 instead — the Apache 2.0 license removes IP complexity, and coding performance is stronger.
Enterprise Architecture / CTOs
Primary constraints: Compliance, vendor risk, TCO, legal.
→ Llama 4 for general-purpose AI features with strong ecosystem support. Supplement with DeepSeek V4 for backend reasoning-heavy tasks if cost economics at scale are critical. Engage legal review on both licenses before proceeding.
→ Key decision factor: If your industry is subject to data residency regulations (healthcare, finance, government), open-weight self-hosting is not just a cost decision — it may be a compliance requirement.
Software Developers / ML Engineers
Primary constraint: Coding performance, fine-tuning flexibility, technical capability ceiling.
→ Qwen 3.7 for coding tasks. Apache 2.0 licensing, SWE-bench competitive performance, and multilingual support make it the technically optimal choice for engineering-focused deployments.
→ Alternative: If your development work is primarily in Python for data science or scientific computing, DeepSeek V4 may offer stronger mathematical reasoning support for complex algorithm generation.
AI Researchers
Primary constraints: Reproducibility, model transparency, research publication requirements.
→ Llama 4 or Qwen 3.7 — both have active research communities and well-documented architectures. For long-context research, Kimi K2.6 provides a useful experimental platform. Consider whether your institution’s open-science requirements necessitate models with fully disclosed training data.
AI Agent Developers
Primary constraints: Tool-calling reliability, structured output, multi-step reasoning.
→ GLM-5.1 for maximum function-calling reliability. Kimi K2.6 if your agents need to read very long documents as part of their task. Llama 4 if ecosystem integrations (LangGraph, AutoGen) matter more than specialist agentic performance.
RAG System Architects
Primary constraints: Long-context retrieval, factual accuracy, hallucination rate.
→ Kimi K2.6 if your documents are long and retrieval completeness matters (legal, medical). Llama 4 if you need ecosystem breadth for the RAG pipeline tooling. Run your own hallucination rate evaluation on your domain data — benchmark hallucination rates rarely transfer directly to domain-specific deployments.
Local / On-Device Deployment
Primary constraints: VRAM budget, latency on consumer hardware, offline capability.
→ Gemma 4 without question for the tightest resource constraints (laptops, mobile, edge hardware). For users with a dedicated consumer GPU (24GB VRAM), Llama 4 in GGUF quantised format is also viable and offers stronger capability.
Decision Matrix
| Use Case | Primary Recommendation | Alternative | Critical Consideration |
|---|---|---|---|
| Coding / Dev Tools | Qwen 3.7 | Llama 4 | Apache 2.0 license simplifies IP |
| Enterprise General AI | Llama 4 | DeepSeek V4 | Validate license at your scale |
| Long-Document / RAG | Kimi K2.6 | Llama 4 | Model TTFT latency at your context length |
| Autonomous Agents | GLM-5.1 | Kimi K2.6 | Test BFCL reliability on your function schema |
| Backend Reasoning at Scale | DeepSeek V4 | Llama 4 | MoE VRAM requirements; geopolitical supply chain review |
| On-Device / Local | Gemma 4 | Llama 4 (GGUF) | VRAM availability determines which variant |
| Consumer-Facing Chat | MiniMax M3 | Llama 4 | Human preference evaluation on your user base |
| Multilingual Applications | Qwen 3.7 | Llama 4 | Validate on your specific language pairs |
Deployment & Infrastructure Guide
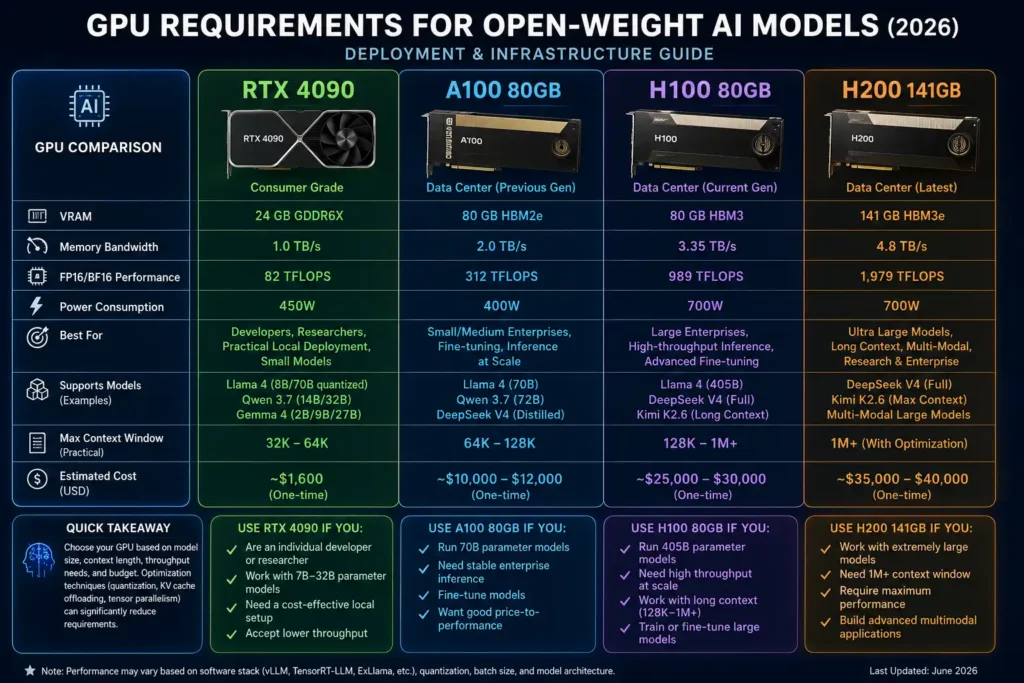
Understanding GPU Requirements
The relationship between model size, precision, and VRAM requirements follows a predictable formula: a model with N billion parameters at FP16 precision requires approximately N × 2 GB of VRAM as a baseline (before KV-cache and activation memory). For example:
- 7B model at FP16: ~14 GB VRAM (fits on RTX 3090/4090)
- 13B model at FP16: ~26 GB VRAM (requires high-end consumer or entry professional GPU)
- 70B model at FP16: ~140 GB VRAM (requires multi-GPU setup with NVLink or distributed inference)
- 70B model at INT4 (aggressive quantisation): ~35 GB VRAM (feasible on A100-40GB or 2× consumer 24GB)
For MoE models, total parameter count determines loading requirements. A 100B parameter MoE model loaded in FP16 requires ~200 GB VRAM total, even though active inference only uses a fraction of that.
Quantisation Formats: A Practical Guide
GGUF (llama.cpp format) The de-facto standard for local deployment. Supports Q4_K_M, Q5_K_M, Q8_0, and other quantisation levels. Compatible with Ollama (the simplest local deployment path), LM Studio, and direct llama.cpp inference. Best choice for: on-device deployment, rapid local prototyping, developer environments.
AWQ (Activation-aware Weight Quantisation) Preferred for production GPU server deployment. Provides better quality-per-bit than naive weight quantisation by calibrating quantisation to the activation distribution. Compatible with vLLM natively. Best choice for: production inference servers where quality matters most at INT4 precision.
GPTQ An older but widely-supported quantisation format. AutoGPTQ is the reference implementation. Compatible with vLLM, TGI, and HuggingFace Transformers. Best choice for: environments where AWQ compatibility is limited or where existing GPTQ workflows are established.
Inference Engine Selection
| Engine | Best For | Throughput | Setup Complexity | Key Feature |
|---|---|---|---|---|
| Ollama | Local dev, single GPU | Moderate | Very Low | One-command model download and serve |
| vLLM | Production, multi-GPU | Very High | Moderate | PagedAttention; industry-standard for serving |
| TGI (HuggingFace) | Production, HF ecosystem | High | Moderate | Deep HuggingFace integration |
| llama.cpp | Edge, CPU/consumer GPU | Moderate | Low | CPU inference possible; GGUF native |
| TensorRT-LLM | NVIDIA production clusters | Highest | High | Maximises H100/H200 throughput |
Fine-Tuning Approaches
LoRA (Low-Rank Adaptation) Adapts model behaviour by training small rank decomposition matrices instead of full weights. Reduces trainable parameters by 100–1000× compared to full fine-tuning. Sufficient for most domain adaptation tasks (custom terminology, output format, style). VRAM requirements for LoRA are significantly lower than full fine-tuning.
QLoRA (Quantised LoRA) Combines LoRA with 4-bit quantisation of the base model, enabling fine-tuning of large models on consumer or single professional GPU hardware. Slightly lower quality than full LoRA but enables training that would otherwise be impossible at the hardware level. The Unsloth library provides optimised QLoRA implementations for most major open-weight models.
Full Fine-Tuning Modifies all model weights. Requires substantial GPU memory and compute. Reserved for cases where LoRA does not achieve required performance, or where the target domain is extremely different from the model’s pre-training distribution. Rarely necessary for most enterprise adaptation tasks.
RLHF / DPO (Alignment Fine-Tuning) Used to align model behaviour with specific preferences, policies, or safety requirements. DPO (Direct Preference Optimisation) has become the practical standard for enterprise alignment fine-tuning, having displaced the more complex RLHF approach for most use cases. TRL (Transformer Reinforcement Learning) library from HuggingFace is the standard implementation.
Expert Insight: The most common fine-tuning mistake in enterprise AI projects is training too early on too little data. Fine-tuning with fewer than a few hundred high-quality, task-representative examples typically degrades general capability more than it improves task-specific performance. The correct sequence is: (1) validate that prompt engineering alone cannot achieve required performance, (2) validate that few-shot prompting with good examples cannot achieve required performance, (3) then fine-tune with a quality-controlled dataset of at minimum several hundred examples, validated against a held-out test set. Teams that skip steps 1 and 2 routinely spend weeks fine-tuning a model to underperform their original prompted baseline.
Key Trends Shaping Open-Weight AI in 2026
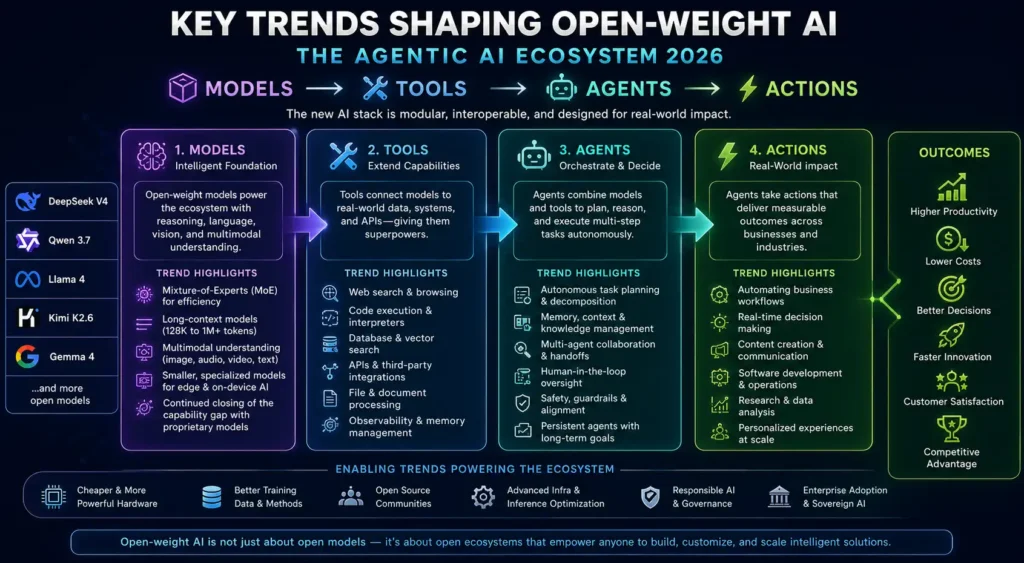
1. Agentic AI Has Crossed the Production Threshold
2024 saw the proliferation of AI agent demos. 2025 was the year of “agent winter” discourse when production deployments failed to live up to demos. 2026 has quietly become the year that agentic AI started working reliably in specific, well-scoped domains. The key shifts: better function-calling reliability in base models (particularly GLM-5.1 and Llama 4), mature orchestration frameworks (LangGraph, AutoGen, CrewAI), and the pragmatic insight that narrow-scope agents with clear success criteria outperform general-purpose agents with ambiguous goals.
2. MoE Has Become the Default Architecture for Frontier-Class Models
The GPU memory economics of MoE have resolved in favour of the architecture for any model targeting frontier capability. Dense models remain the standard for small, efficient, edge-deployable models (Gemma 4 lineage). For the highest capability tier, MoE’s ability to scale total parameters without linearly scaling inference compute has won the architectural debate.
3. On-Device AI Is a Real Product Category
Neural Processing Units (NPUs) in consumer hardware — Apple Silicon M-series, Qualcomm Snapdragon X Elite, Intel Meteor Lake — have reached performance levels that make 7B-class model inference genuinely fast (several tokens per second) on consumer devices. This has created a real product category: offline-first AI that processes sensitive data entirely on-device. Gemma 4 and Llama 4 (smaller variants) are the primary beneficiaries in the open-weight ecosystem.
4. Sovereign AI Infrastructure is a National Priority
Multiple governments — the EU, India, UAE, Saudi Arabia, and others — have announced sovereign AI programmes that involve procuring and customising open-weight models on national cloud infrastructure. This is the highest-stakes manifestation of the data sovereignty argument, and it has materially accelerated enterprise acceptance of open-weight AI. Llama 4 is the most common foundation model for these national AI initiatives due to its ecosystem and deployment flexibility.
5. Quantisation Quality Gap Has Nearly Closed
INT4 quantisation in 2023 produced noticeably degraded outputs on complex tasks. INT4 quantisation in 2026, using techniques like AWQ and GPTQ with proper calibration datasets, is nearly indistinguishable from FP16 on most tasks. This means the VRAM requirements for production-quality inference have effectively halved, democratising access to larger, more capable models on mid-tier GPU infrastructure.
Challenges of Open-Weight AI Adoption
1. Infrastructure Ownership and MLOps Maturity
Self-hosting a model means owning every layer of the infrastructure stack: GPU procurement or cloud leasing, inference engine deployment and scaling, monitoring, availability, and model update management. For organisations without dedicated ML engineering, this is a non-trivial commitment. The total cost of ownership must account for engineering time, not just GPU costs.
Practical mitigation: Managed open-weight inference providers (Together AI, Replicate, Modal, Anyscale) offer a middle path — you use open-weight models without managing inference infrastructure directly. The trade-off: less control and higher per-token cost than self-managed infrastructure, but dramatically lower operational overhead.
2. Hallucination Management and Evaluation
Open-weight models do not carry the safety alignment investment of frontier closed models. Hallucination rates, refusal behaviour, and response calibration vary significantly across model variants and fine-tunes. Production deployments require:
- A held-out evaluation set representative of real inputs
- Automated factual consistency checking for high-stakes outputs
- Human review workflows for outputs above certain risk thresholds
- Robust RAG pipelines that ground generation in verified source documents
3. Fine-Tuning Complexity
The barrier to entry for fine-tuning has fallen dramatically (QLoRA on consumer hardware is now practical), but the barrier to effective fine-tuning remains high. Data quality, dataset construction, hyperparameter selection, evaluation methodology, and avoiding catastrophic forgetting all require expertise that most software teams do not have on staff. Budget for data curation and ML expertise in addition to compute costs.
4. Licence Compliance Tracking
As open-weight model landscapes evolve, licences change. A model that was Apache 2.0 today may add commercial restrictions in a future version. Your production application may run on a specific model version for years — the licence terms at deployment time matter. Maintain a software bill of materials (SBOM) that includes AI models and their licence versions, just as you would for open-source software libraries.
5. Model Update and Drift Management
Closed API providers handle model updates automatically (sometimes with unannounced changes that alter output behaviour). Self-hosted models give you control over updates but also the responsibility. When a new model version is released, it requires evaluation before deployment. Maintaining multiple model versions in production for A/B testing requires additional infrastructure.
Final Verdict & Rankings
Top-Tier Rankings by Deployment Priority
| Rank | Model | Best For | Defining Strength | Critical Limitation |
|---|---|---|---|---|
| 1 | Llama 4 | Enterprise / General Purpose | Ecosystem & Versatility | Not best-in-class on any single dimension |
| 2 | Qwen 3.7 | Coding & Multilingual | Apache 2.0 + Coding Performance | Dense architecture = higher inference cost at scale |
| 3 | DeepSeek V4 | High-Scale Backend Reasoning | MoE efficiency | Geopolitical/supply-chain considerations |
| 4 | Kimi K2.6 | Long-Context / RAG / Agents | Ultra-long context | High TTFT; limited ecosystem |
| 5 | GLM-5.1 | Autonomous Agents | Function-calling reliability | Smaller ecosystem |
| 6 | Gemma 4 | On-Device / Edge | Efficiency per parameter | Capability ceiling |
| 7 | MiniMax M3 | Consumer Chat / Content | Stylistic nuance | Weakest on technical tasks |
The Honest Conclusion
There is no universally “best” open-weight model in 2026, and any guide claiming otherwise is prioritising ranking simplicity over accuracy.
Choose Llama 4 when you need to minimise deployment risk and maximise ecosystem support. Its performance across every dimension is competitive without being the leader in any single one — which is exactly what you want for a general-purpose foundation.
Choose Qwen 3.7 when coding is your core value proposition and licensing clarity matters. The Apache 2.0 licence is a genuine commercial advantage.
Choose DeepSeek V4 when reasoning-to-compute ratio is your primary metric and you have evaluated the licensing and supply-chain considerations for your context.
Choose Kimi K2.6 when your application genuinely requires processing documents of 200k tokens or more and you can absorb higher TTFT.
Choose GLM-5.1 when you are building production agents with complex tool-use requirements and reliability matters more than general capability breadth.
Choose Gemma 4 when your deployment target is on-device and you cannot afford the infrastructure for larger models.
Choose MiniMax M3 when your user-facing quality metric is human preference rather than technical benchmark performance.
References & Further Reading
Official Model Documentation and Technical Reports
- DeepSeek V3 Technical Report — https://arxiv.org/abs/2412.19437 (V4 report forthcoming; V3 establishes architectural baseline)
- Qwen Technical Reports — https://qwenlm.github.io/ (official documentation and papers)
- Meta Llama 4 Technical Report — Available at https://ai.meta.com/llama/
- Google Gemma Documentation — https://ai.google.dev/gemma
- Kimi Technical Documentation — https://kimi.moonshot.cn/
Benchmark Sources
- Hugging Face Open LLM Leaderboard — https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard
- LMSYS Chatbot Arena — https://lmarena.ai/
- LiveBench — https://livebench.ai/ (contamination-resistant benchmark)
- Berkeley Function-Calling Leaderboard (BFCL) — https://gorilla.cs.berkeley.edu/leaderboard.html
- SWE-bench Verified — https://www.swebench.com/
Seminal Research Papers
- “Attention Is All You Need” (Vaswani et al., 2017) — Foundational transformer architecture
- “LoRA: Low-Rank Adaptation of Large Language Models” (Hu et al., 2021) — arXiv:2106.09685
- “QLoRA: Efficient Finetuning of Quantized LLMs” (Dettmers et al., 2023) — arXiv:2305.14314
- “Mixtral of Experts” (Mistral AI, 2024) — First widely deployed open-weight MoE model
- “RLHF: Training language models to follow instructions” (Ouyang et al., 2022) — Foundation for alignment fine-tuning
Inference and Deployment Infrastructure
- vLLM — https://vllm.ai/ | GitHub: https://github.com/vllm-project/vllm
- Ollama — https://ollama.com/
- Text Generation Inference (TGI) — https://github.com/huggingface/text-generation-inference
- llama.cpp — https://github.com/ggml-org/llama.cpp
- Unsloth (Fine-tuning) — https://unsloth.ai/
Agentic AI Frameworks
- LangGraph — https://langchain-ai.github.io/langgraph/
- AutoGen — https://microsoft.github.io/autogen/
- CrewAI — https://crewai.com/
Licensing Resources
- Open Source Initiative (OSI) License List — https://opensource.org/licenses
- AI Model License Comparison (RAIL Initiative) — https://www.licenses.ai/

FAQs
What is the best open-weight AI model in 2026? There is no single answer because “best” depends on your use case. For general-purpose enterprise deployment with minimal risk, Llama 4 is the strongest choice due to its ecosystem. For coding specifically, Qwen 3.7 leads. For mathematical reasoning at scale, DeepSeek V4. Consult the decision matrix in this guide for your specific profile.
What is the difference between open-weight and open-source AI? Open-weight means the trained model weights are publicly available for download and deployment. Open-source (by the OSI definition) additionally requires that training data, training code, and the full reproduction pipeline are available under an approved license. Most “open” models in 2026 are open-weight only — the training data remains proprietary.
How much GPU memory do I need to self-host an open-weight model? As a rule of thumb: multiply the model’s parameter count (in billions) by 2 to get the approximate FP16 VRAM requirement in gigabytes. A 7B model needs ~14 GB; a 70B model needs ~140 GB. Using INT4 quantisation roughly divides this by 4. For consumer hardware, 7B–13B quantised models are practical on a single 24GB GPU.
Which open-weight model is best for coding? Qwen 3.7 consistently performs best on coding benchmarks (HumanEval+, BigCodeBench) among the open-weight models evaluated here. For repo-level coding tasks (the more practical test), SWE-bench performance should guide your selection — consult current leaderboard data at swebench.com.
Is DeepSeek safe to use for enterprise deployments? DeepSeek V4 weights can be self-hosted, meaning inference can run entirely on your own infrastructure without data leaving your environment. This mitigates data privacy concerns. However, several enterprises and government agencies have raised concerns about the company’s Chinese jurisdiction and the potential implications under Chinese data law. Consult your security, legal, and compliance teams. This is an organisational risk assessment, not a purely technical one.
Can open-weight models match GPT-4o or Claude? For many practical tasks — document processing, code generation, data extraction, summarisation — top open-weight models in 2026 produce commercially acceptable outputs that are competitive with or comparable to closed frontier models. For the most demanding reasoning tasks, creative synthesis, or nuanced instruction following, frontier closed models (GPT-4o, Claude Opus) maintain a measurable lead. The capability gap has narrowed substantially since 2024 but has not fully closed at the frontier.
What does fine-tuning actually cost? For LoRA fine-tuning on a 7B model with a dataset of 1,000 examples: a few dollars on a rented GPU instance (e.g., an A100 for a few hours). For full fine-tuning of a 70B model: potentially tens of thousands of dollars in compute, plus the data preparation cost. The bigger cost is almost always data curation, not compute. High-quality training examples require expert human review.
What inference engine should I use? For local development and testing: Ollama (simplest setup). For production single-server deployment with high throughput: vLLM (best performance). For multi-node large-scale inference on NVIDIA hardware: TensorRT-LLM (maximum throughput on H100/H200). For CPU or low-VRAM deployment: llama.cpp.
How do I evaluate which model is right for my use case? Start with your actual data. Take 100–200 representative examples from your production task, define a clear success metric, and run inference on each candidate model. Do not rely solely on public benchmarks — they frequently mispredict relative performance on domain-specific tasks. Your evaluation set is the authoritative signal. Small businesses exploring AI adoption should also evaluate practical business-focused AI platforms.
Are open-weight model licences really a risk? Yes. The Llama Community License, for example, includes a provision that kicks in at scale and requires commercial agreements for large deployments. Several open-weight models prohibit use for training competing foundation models. Some restrict modification and redistribution. These terms have real legal implications. Every production AI deployment should include a legal review of the model’s licence at the version being deployed.
What is quantisation and should I use it? Quantisation reduces the numerical precision of model weights (from FP16 to INT8 or INT4), reducing memory requirements and often increasing inference speed at the cost of some model quality. Modern quantisation methods (AWQ, GPTQ) preserve the vast majority of capability in well-maintained quantisation pipelines. For most production use cases, INT4 or INT8 quantised models are appropriate. For highest-stakes outputs where quality margins matter, FP16 or FP8 is preferable if your hardware supports it.
This guide represents the state of open-weight AI as evaluated through mid-2026. The field moves rapidly — specific benchmark rankings and model releases should be verified against current primary sources. All licensing information should be reviewed directly against official model documentation before production deployment.
If you found this guide useful, the single most valuable thing you can do is validate our recommendations against your own data and share your findings with your team. Real-world deployment experience will always outperform any benchmark comparison.
Continue Reading
- Google Gemini New Features 2026
- AI Coding Assistants
- DiffusionGemma Review
- Best Free AI Image Generators
- Best AI Tools for Small Businesses
Technology Perspective
Technology continues to transform industries through artificial intelligence, cloud computing, automation, cybersecurity, digital platforms, and data-driven decision making. As organizations increasingly adopt digital solutions, understanding emerging technologies becomes essential for businesses, professionals, and consumers. DGM News regularly covers these developments through expert analysis, technology news, and educational resources.
Innovation Outlook
Rapid advances in artificial intelligence, automation, machine learning, cloud infrastructure, and digital transformation continue reshaping global industries. Monitoring these developments helps organizations adapt to changing technologies, improve efficiency, and prepare for future innovation.
Did you know?
Artificial Intelligence is expected to influence nearly every major industry over the coming decade, from healthcare and finance to transportation, manufacturing, education, and entertainment.
AI, Machine Learning, Deep Learning and Generative AI Explained
Google AI Updates
About DGM News
DGM News is an independent digital publication delivering the latest Technology News, AI News, and FinTech News. We provide expert insights on startups, innovation, cybersecurity, software, business, gadgets, cloud computing, artificial intelligence, and emerging technologies. Our mission is to publish informative, accurate, and regularly updated content that helps readers stay informed in today's rapidly evolving digital landscape.
Since our editorial focus includes technology, artificial intelligence, and financial technology, we continuously expand our coverage as new innovations emerge.
Editorial Standards
Every article published on DGM News undergoes editorial review before publication. We prioritize factual accuracy, clarity, transparency, and reader value while following responsible digital publishing practices.
Research Methodology
Our editorial team researches publicly available information from official announcements, technical documentation, research publications, developer resources, reputable industry reports, and trusted public sources whenever applicable. Information is reviewed to improve clarity and accuracy before publication.
Fact-Checking Policy
We make reasonable efforts to verify factual information before publishing. Articles are reviewed for accuracy, consistency, and relevance. If significant developments occur after publication, content may be revised to reflect updated information.
Update Policy
Technology evolves rapidly. Articles may be reviewed and updated periodically to reflect software releases, AI developments, security advisories, regulatory updates, product launches, and other important industry changes.
Source Verification
Whenever possible, DGM News reviews information using official company announcements, technical documentation, research publications, government resources, publicly available reports, and reputable industry references before updating articles.
Editorial Independence
DGM News maintains editorial independence in all publishing decisions. Editorial content is produced independently and is intended to provide balanced, informative, and reader-focused coverage without influence from advertisers or commercial partnerships.
AI Usage Disclosure
Artificial intelligence tools may assist with research organization, grammar improvement, formatting, or editorial workflows. Every article is reviewed by human editors before publication to help maintain quality, clarity, and factual accuracy.
Corrections Policy
Accuracy is important to us. If readers identify outdated information or factual inaccuracies, they are encouraged to contact our editorial team. Verified corrections are reviewed and incorporated whenever appropriate.
Reader Feedback
Reader feedback helps improve our journalism. We welcome suggestions, corrections, and constructive feedback through our Contact page to continuously improve the quality of our reporting.
Last Editorial Review
This article follows the DGM News editorial review process and may be updated periodically as new information becomes available.
Why Trust DGM News?
DGM News is committed to publishing technology journalism that emphasizes accuracy, transparency, editorial independence, and regularly updated information. Our editorial process is designed to provide readers with reliable coverage of technology, AI, fintech, startups, and digital innovation.
DGM News Resources
Topics We Cover
Artificial Intelligence • AI Tools • Machine Learning • FinTech • Cybersecurity • Cloud Computing • Programming • Software Development • Gadgets • Mobile Technology • Business Technology • Startups • Digital Marketing • Blockchain • Cryptocurrency • Science • Innovation • Consumer Technology • Enterprise Technology • Automation
