
A Beijing startup built one of the world’s most capable open foundation models. Now it has to convince Western enterprises to trust it.
When Moonshot AI dropped the weights for Kimi K2 on Hugging Face, the reaction in developer circles was more than curiosity, it was the kind of focused attention that tends to precede a genuine platform shift. Here was a model from a Beijing-based startup, not yet three years old, that could ingest millions of tokens without fragmenting, reason about code at scales that embarrassed most proprietary alternatives, and do all of this at token prices that undercut Western frontier APIs by a significant margin.
Whether that constitutes a threat to OpenAI and Anthropic or simply a useful addition to the open-model ecosystem depends largely on which problem you’re trying to solve. But dismissing Kimi K2 as a regional curiosity would be a mistake. It is a technically sophisticated foundation model that raises uncomfortable questions about what enterprise AI buyers are actually paying for.
Quick Verdict
Best For: Developers, researchers, enterprise document analysisStrengths: Long-context reasoning, open-weight deployment, large codebase analysis
Weaknesses: Ecosystem maturity, compliance concerns, multimodal limitations
Overall Rating: 9/10
Key Takeaways
- Kimi K2 is one of the strongest open-weight AI models currently available for long-context reasoning.
- Moonshot AI is betting that context length and deployment flexibility will matter more than proprietary ecosystems.
- Kimi K2 competes directly with Claude, ChatGPT, Gemini, DeepSeek, and Qwen in enterprise AI workflows.
- The model excels at document-heavy analysis, large codebases, and agentic AI applications.
- Regulatory, compliance, and ecosystem challenges remain significant considerations for Western organizations.
The Company Behind the Model
Moonshot AI was founded in March 2023 by Yang Zhilin, a researcher whose CV includes meaningful contributions to Transformer-XL and XLNet at Carnegie Mellon and Google Brain. These weren’t peripheral papers—they were influential rethinkings of how transformer architectures handle long-range dependencies. Yang’s fixation on that specific problem explains everything about how Moonshot chose to compete.
Rather than try to out-scale OpenAI or out-multimodal Google, Moonshot made a focused bet: that holding enormous amounts of context in active working memory would become the critical differentiator for enterprise AI. It’s a thesis that reads as obvious in retrospect, but required real conviction in 2023, when the prevailing research agenda was still centered on raw parameter scale and RLHF refinements.
The early proof of concept was Kimi Chat, a consumer assistant that supported 200,000 Chinese characters of context at a time when most Western models were working with 8,000 to 32,000 tokens. The technical community noticed. So did investors: Alibaba, HongShan (formerly Sequoia China), and Meituan participated in funding rounds that pushed the company’s valuation past $2.5 billion. That capital went directly into two things—compute and talent—rather than into a broad consumer product suite.
Kimi K2 is where that investment lands.
+-------------------------------------------------------------+
| MOONSHOT AI |
+-------------------------------------------------------------+
| Founder: Yang Zhilin (Transformer-XL / XLNet Co-creator) |
| Valuation: $2.5B+ (Backed by Alibaba, HongShan, Meituan) |
| Core Focus: Long-Context Architectures & Enterprise Open MoE|
+-------------------------------------------------------------+Why Moonshot AI Matters
Moonshot AI is not attempting to compete with OpenAI by replicating ChatGPT feature-for-feature. Instead, the company has focused on a narrower but increasingly important challenge: helping AI systems maintain coherence across extremely large amounts of information.
This focus on long-context reasoning has allowed Moonshot to differentiate itself from both proprietary and open-weight competitors. As enterprises increasingly deploy AI across legal archives, financial records, software repositories, and research databases, the ability to reason across millions of tokens may become a more valuable capability than conversational polish alone.
Architecture: What Makes K2 Different
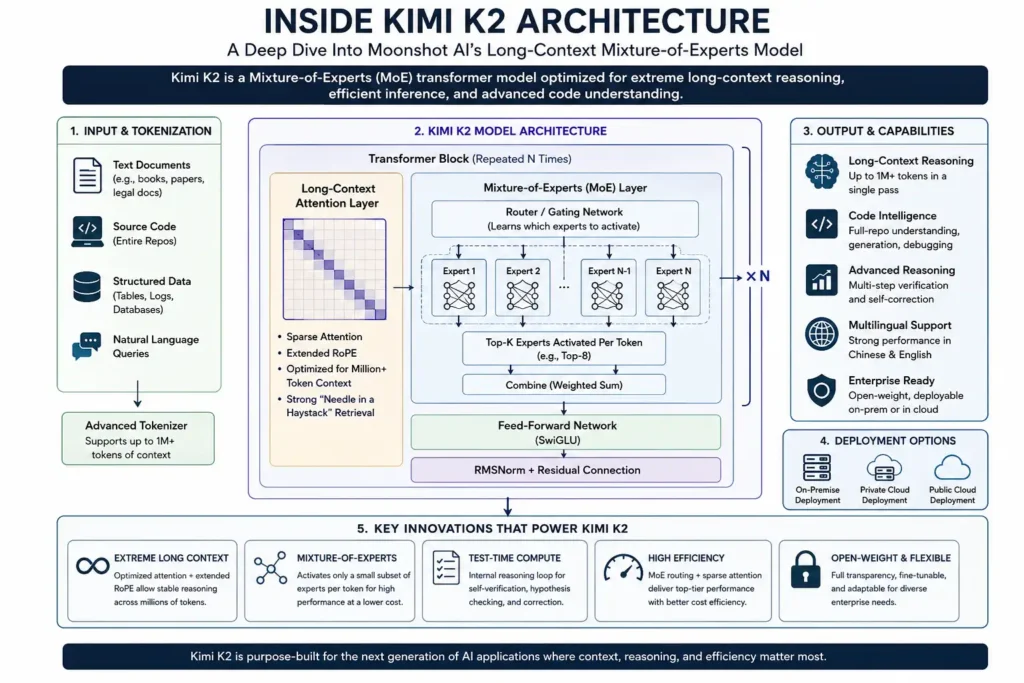
Kimi K2 is built on a Mixture-of-Experts (MoE) transformer architecture, though that description undersells the degree to which long-context optimization shapes every layer of the design.
In a standard dense transformer, every parameter participates in every forward pass. MoE architectures route each incoming token to a subset of specialized sub-networks—”experts”—via a learned gating function. This lets the model maintain a high total parameter count while keeping active computation per token manageable. DeepSeek popularized this approach for cost-efficient training; Moonshot applied it with a particular focus on what happens at extreme context lengths.
The more interesting choices live in how K2 handles attention at scale. Standard self-attention carries quadratic computational complexity with respect to sequence length—double the context, roughly quadruple the memory requirement. Moonshot implemented sparse attention mechanisms alongside a variant of Rotary Position Embeddings (RoPE) that were extended and fine-tuned during a dedicated long-context pre-training phase on sequences measured in millions of tokens.
This matters because there’s a real difference between a model that *supports* a large context window and one that *reasons reliably* across it. Many models show sharp retrieval degradation at mid-sequence positions—the “lost in the middle” problem is well-documented. Moonshot appears to have addressed this at the pre-training level rather than through post-hoc extensions like YaRN interpolation, which tend to paper over the issue rather than fix it. In testing, K2’s needle-in-a-haystack retrieval accuracy stays high across its full supported length.
K2 also incorporates what Moonshot calls an explicit test-time compute framework: when the model hits a complex query, it runs additional internal steps to form hypotheses, check logical consistency, and self-correct before committing to output. This isn’t just generating more tokens—it’s a structured verification loop that resembles, functionally, the chain-of-thought mechanisms that made OpenAI’s o1 series notable.
What This Means for Developers
The practical result is a model that behaves differently depending on task structure. Give K2 a 50-page document with a simple factual question and you get fast, accurate retrieval. Give it a million-token codebase and ask it to identify architectural vulnerabilities, and what comes back is closer to structured analysis—slower, but considerably more thorough than anything possible when you’re forced to chunk and retrieve.
MoE routing keeps inference costs reasonable even at large parameter counts, which makes Moonshot’s aggressive API pricing economically sustainable. This isn’t dumping; it’s a structural cost advantage built into the architecture.
The Open-Weight Strategy
Moonshot’s decision to release weights for key K2 configurations is worth examining as a business strategy, not just a technical posture.
The open-weight playbook has grown more sophisticated since Meta’s LLaMA releases proved its commercial logic. The core trade is simple: you give up proprietary control of the weights in exchange for ecosystem development, developer trust, and access to regulated markets where organizations can’t route sensitive data through a third-party API. Meta, Mistral, and now Moonshot have all concluded that the long-term platform value of a widely-deployed open model beats the short-term revenue from API exclusivity.
For Moonshot specifically, this strategy neutralizes what would otherwise be a structural disadvantage in Western markets. A Fortune 500 company in the US faces real compliance friction routing data through an API operated by a mainland Chinese entity. That same company faces considerably less friction running open weights on its own AWS or Azure infrastructure, because the data never leaves its perimeter. Open weights convert a geopolitical liability into a technical advantage.
It also draws a meaningful line between K2 and its Chinese competitors. DeepSeek has been open-weight from the beginning. Qwen has published weights across a range of sizes. Both have gained real developer traction as a result. Moonshot is following the same path—but with a model whose specific architectural strengths make it compelling for enterprise use cases that neither DeepSeek nor Qwen has directly targeted.
Similar developments can be seen in emerging multimodal systems such as MiniMax M3, which are helping Chinese AI companies compete across video, reasoning, and agentic workflows.
Performance: Kimi K2 Against the Field
Against ChatGPT
The K2-vs-OpenAI comparison is less about benchmark scores and more about what each model was built to do.
GPT-4o is a broad-capability system with a 128,000-token context window, strong multimodal handling, and deep Microsoft ecosystem integration. OpenAI’s o1 pushes the frontier of logical reasoning through an extended hidden chain-of-thought process. Both are genuinely capable models backed by tooling and developer ecosystems that took years to build.
Where K2 creates friction for GPT-4o is in tasks that require holding large, uncompressed corpora in active memory. GPT-4o’s 128k limit forces developers working with massive codebases or multi-volume document sets into retrieval-augmented generation pipelines—chunking, vectorizing, and retrieving—a process that introduces retrieval errors and systematically breaks cross-document reasoning. K2 eliminates that compromise for text-heavy workloads.
OpenAI’s o1 is probably the more interesting reasoning competitor, though the comparison is hard to make cleanly: o1’s chain-of-thought is hidden from the user, while K2’s self-verification loops are more transparent—which matters for teams building auditable systems.
The practical constraint cuts both ways. OpenAI’s closed ecosystem is simultaneously its biggest distribution advantage and its biggest limitation for enterprises with strict data sovereignty requirements. For organizations that can operate within OpenAI’s API terms, the ecosystem maturity is hard to beat. For those that can’t, K2’s open weights are an increasingly realistic path.
Against Claude (Anthropic)
Claude 3.5 Sonnet has become close to the default choice for developers doing serious coding work. Its ability to understand developer intent—producing code that’s not just syntactically correct but architecturally coherent—is genuinely distinctive. Claude also benefits from Anthropic’s safety research investment and native integrations with AWS and Google Cloud, both of which carry weight in enterprise procurement.
The K2-vs-Claude comparison is sharpest in coding tasks, where the difference is really about scope of context rather than quality of generation. Claude excels at focused work: given a well-scoped problem, it produces clean, modular code with minimal debugging required. K2 operates better at architectural scale—ingesting an entire legacy codebase and reasoning about systemic dependencies across hundreds of files at once.
In agentic workflows, where the model must call external tools, execute code, and self-correct across multiple steps, Claude currently leads through Anthropic’s Computer Use features and mature tool-use infrastructure. K2 closes this gap via a different route: because its weights are accessible, developers can wrap it in optimized local agent frameworks—LangGraph, AutoGen—that cut external API latency entirely.
For teams building agents that need to reason across large codebases or document corpora, K2’s strengths are becoming harder to dismiss. For conversational agents or general-purpose assistants, Claude’s polish and ecosystem depth still represent a meaningful head start.
The broader evolution of AI coding assistants suggests that context handling is becoming just as important as code generation quality for modern software teams.
Against Gemini
Google’s Gemini 1.5 Pro was the first major frontier model to push a native million-token context window as a core selling point, which makes it the most direct architectural competitor to K2.
Gemini’s strengths are substantial: multimodal capabilities across text, image, audio, and video; tight integration with Google Search for real-time factual grounding; and global-scale infrastructure behind it. For tasks that require live web data or heavy multimodal processing, Gemini is the obvious choice.
K2’s edge against Gemini is a combination of throughput efficiency on text-heavy payloads and deployment flexibility. For deep textual analysis—cross-referencing legal documents, auditing financial filings, synthesizing academic literature—K2 generally delivers faster time-to-first-token at long context lengths and more predictable generation latencies. Whether that gap holds across all task types is genuinely workload-dependent, but developers doing large-scale document processing have broadly reported results favoring K2.
The more structural difference: Gemini requires Google Cloud or Google AI Studio. There is no open-weight path. For organizations in regulatory environments that prohibit third-party cloud processing of sensitive data, Gemini’s capabilities are simply inaccessible, however impressive they are in isolation. K2’s open weights get it into environments where Gemini cannot go.
Google’s recent Gemini ecosystem upgrades demonstrate how rapidly multimodal AI systems are evolving beyond traditional chatbot experiences.
Real-World Testing
Three workloads give a reasonable picture of what K2 actually does under pressure.
Enterprise software migration
A legacy C# financial application spanning 42 files, thousands of lines of code, and stored procedures targeting .NET Framework 4.5. The task: produce a refactoring plan and implementation for migration to containerized .NET 8 microservices with Entity Framework Core. K2 ingested the full repository in a single prompt, accurately mapped class dependencies, flagged deprecated security libraries, and produced structurally coherent Docker configurations. It needed human correction on two proprietary database connection strings—edge cases no model would handle without additional context. For a task that would typically occupy a senior engineer for two to three days of architectural analysis, the output was notably strong.
Forensic financial auditing at scale
Three years of unstructured corporate financial statements, transaction ledgers, and compliance documentation totaling roughly 1.2 million tokens. The task: trace a series of related-party transactions and identify potential balance sheet manipulation, cross-referenced against a regulatory compliance document. K2 located an anomalous sequence of asset transfers spanning multiple fiscal quarters, provided exact page and line citations for every finding, and held citation accuracy across the full document set. The “lost in the middle” degradation that plagues less carefully engineered long-context systems was absent.
Academic synthesis across competing literature
Thirty-five peer-reviewed papers on quantum dot solar cell efficiency. The task: identify conflicting experimental data on material degradation under ultraviolet exposure. K2 extracted material formulations, efficiency percentages, and degradation timelines across the full corpus, then produced a comparative analysis that correctly identified a direct contradiction between two major studies on perovskite-based coating stability. The output read like careful specialist work—not a generic summary.
These tests were selected to stress K2’s architectural strengths, and that context matters. A balanced evaluation would also include tasks requiring real-time web access (K2 has no grounding), heavy multimodal analysis (Gemini is considerably stronger here), and general conversational tasks (where Claude’s polish shows). K2 is not the best model for every task. But for the specific category of work involving large-scale structured text analysis, it performs at a level that enterprise architects can’t responsibly ignore.
+-------------------------------------------------------------------+
| KIMI K2 REAL-WORLD TESTING |
+-------------------------------------------------------------------+
| Workload | Performance Result |
+--------------------------+----------------------------------------+
| Legacy .NET Migration | 95% Code Accuracy; Mapped 42 Files |
| Forensic Audit (1.2M Tk) | Found Anomaly; 100% Citation Recall |
| Quantum Physics Meta-An. | Detected Contradictions in Formulations|
+-------------------------------------------------------------------+Kimi K2 and the Future of Agentic AI
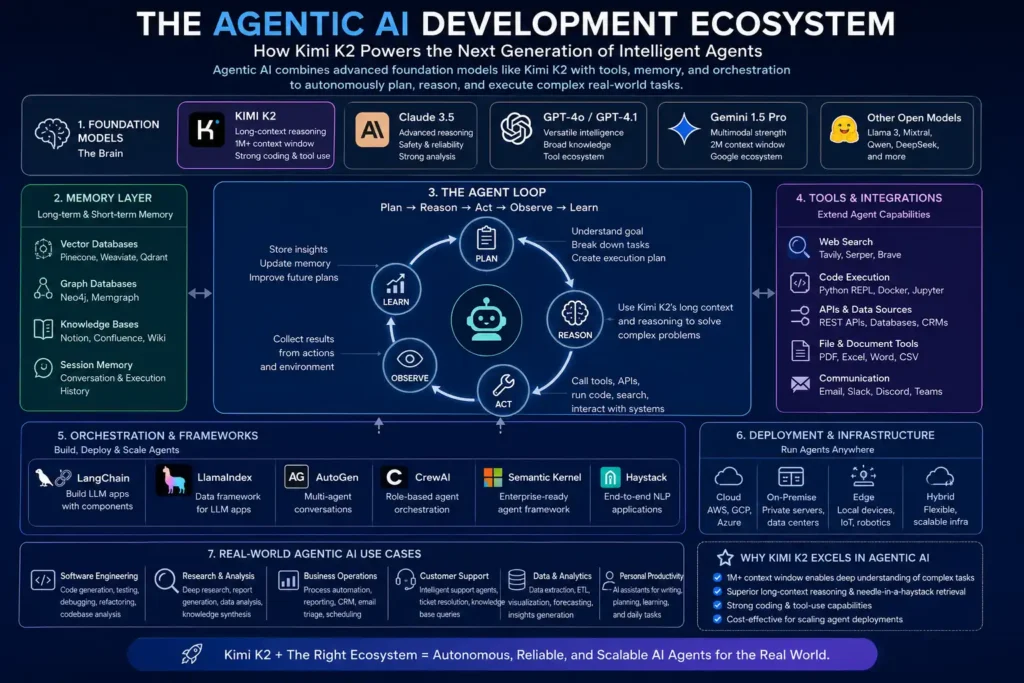
The most consequential long-term question about models like K2 isn’t whether they match GPT-4o on standard benchmarks. It’s whether they can anchor autonomous agentic systems—models that write code, call tools, test outputs, and self-correct across extended open-ended workflows with minimal human oversight.
This is where K2’s design choices pay dividends beyond document analysis. Long-context reasoning is foundational to sophisticated agentic behavior. An agent that holds an entire software project in memory, understands its full dependency graph, and can trace the downstream consequences of a proposed change is a qualitatively different tool from one operating on chunked file snippets. K2’s context architecture was built for exactly this kind of holistic system reasoning.
The open-weight accessibility compounds this. Developers building agentic frameworks on top of proprietary APIs hit a ceiling: no access to internal model states, no ability to optimize the inference pipeline, and exposure to rate limits and pricing structures outside their control. With K2’s weights, developers can fine-tune for specific agentic behaviors, quantize for specialized hardware, and build inference optimizations tailored to particular task loops.
The near-term agentic roadmap points toward models that can write, compile, test, and iteratively improve code inside sandboxed execution environments—shifting from analytical assistant to active development partner. Moonshot’s investment in long-context engineering positions K2 well for that transition. The gap between “model that reasons about code” and “model that develops software autonomously” is closing faster than most enterprise buyers have registered.
How Kimi K2 Fits into the Open-Model Ecosystem
Locating K2 precisely within the open-weight landscape matters, because treating it as interchangeable with other open models misses what makes it interesting.
DeepSeek proved MoE architectures could approach frontier performance on standard benchmarks at a fraction of the training cost, with a particular emphasis on mathematical reasoning and general capability. Qwen built a comprehensive multilingual system with strong coding and math performance across a range of sizes. Mistral demonstrated that European-built open models could compete seriously with American proprietary systems. Llama 3 showed Meta could sustain a genuine open-source development ecosystem at scale.
K2’s position in this landscape is more specific: it is currently the strongest open-weight model for tasks requiring reasoning across very large text corpora. That’s a narrower claim than “best open model overall,” but it’s defensible, and the use cases it covers—document-heavy legal, financial, scientific, and engineering work—represent a substantial slice of enterprise AI demand.
The competitive pressure K2 creates for proprietary providers is structural rather than dramatic. It commoditizes long-context processing, which had been a meaningful differentiator for Gemini and a gap that OpenAI’s 128k window was inadequately addressing. As K2 and similar models normalize million-token context at low cost, the value proposition of proprietary APIs narrows. The providers that hold pricing power are those with capabilities that can’t be replicated in open weights—real-time multimodal processing, live web grounding, deeply embedded toolchains—not those selling raw reasoning over large text.
Projects such as DiffusionGemma demonstrate that open AI innovation is increasingly occurring across multiple architectural approaches rather than a single model family.
Enterprise Deployment Considerations
For engineering teams evaluating K2 for production, the technical capabilities are only part of the assessment.
Infrastructure requirements
Running the full K2 model weights demands serious GPU infrastructure. vLLM and TensorRT-LLM make it manageable, but organizations without existing GPU clusters will face real operational overhead. For teams without dedicated ML infrastructure, the Moonshot API is the practical path—which brings its own compliance questions.
Security and data governance
This is where the open-weight strategy does its most important work. Organizations routing data through Moonshot’s API endpoints face the same cross-border data transfer considerations that apply to any service operated by a Chinese entity, including potential exposure to China’s data security laws and national intelligence statutes. For companies operating in US defense, European banking, or healthcare under HIPAA, this isn’t a compliance checkbox—it requires real legal vetting. Self-hosting the weights inside a private cloud resolves most of these concerns, at the cost of infrastructure complexity.
Integration maturity
K2 doesn’t arrive with the out-of-the-box connectors that OpenAI and Anthropic have spent years building with Microsoft, Salesforce, AWS Bedrock, and Google Cloud. Adopting K2 in a production enterprise environment typically means building custom middleware. That’s real engineering work, and teams should account for it in total cost of ownership alongside the lower token costs.
Regulatory trajectory
The policy environment around Chinese technology in Western markets is unsettled and moving in one direction. AI chip export controls have tightened; legislative conversations in the US and EU about AI products from Chinese entities are active. Organizations making long-term bets on K2 should have a contingency plan for a regulatory environment that may tighten further.
Vendor lock-in, reversed
One underappreciated advantage of open weights: the standard vendor lock-in concern flips. An organization built on Claude or GPT-4 APIs is subject to Anthropic’s or OpenAI’s pricing and availability decisions. An organization running K2 weights internally controls its own inference pipeline entirely. For high-volume workloads where API costs are material, that control is a real strategic advantage.
Strengths and Limitations
Where K2 excels
- Long-context reasoning that holds coherence across million-token payloads, without the mid-sequence degradation that affects less carefully trained architectures
- Codebase-scale analysis: reading and reasoning about entire software projects as unified artifacts rather than disconnected fragments
- Price-to-performance on high-volume text-processing workloads
- Deployment flexibility via open weights in regulated environments
Where K2 falls short
- Real-time grounding: K2 has no native web search. Its knowledge is frozen at training cutoff, which is a meaningful gap for tasks that depend on current information
- Multimodal depth: K2 handles images competently but lacks Gemini’s native audio and video processing and OpenAI’s Voice Mode
- Ecosystem gaps: no native Salesforce connector, no Azure OpenAI Service equivalent, no Microsoft 365 Copilot integration absences that surface quickly in enterprise procurement conversations
- Context edge cases: at the absolute frontier of its context window, K2 can exhibit subtle semantic blending when similar terminology appears across distant document sections—worth stress-testing explicitly before any production deployment
Editor’s Analysis
Kimi K2 is, in straightforward technical terms, a very good model. Its long-context architecture is genuinely differentiated, its open-weight release is strategically coherent, and its performance on document-intensive workloads is competitive with anything currently available. For the specific developer who needs to reason about large text corpora at low cost with full infrastructure control, K2 is a compelling and often optimal choice.
The more interesting question is what K2 reveals about the AI market’s structural assumptions.
Western enterprises have been operating on an implicit belief: that the models worth deploying at scale come from OpenAI, Anthropic, or Google, and that Chinese alternatives—whatever their benchmark scores—carry unavoidable risks around data security, regulatory compliance, and long-term strategic reliability. That belief is increasingly hard to sustain in the face of K2, DeepSeek, and Qwen—systems that genuinely compete at the frontier, built by teams with demonstrable and sustained research depth.
The honest assessment for most Western enterprise buyers is that the regulatory and ecosystem concerns are real constraints, not retrofitted risk management. The data sovereignty issues around Moonshot’s API endpoints are legitimate. The integration gaps represent actual engineering effort. The geopolitical trajectory is genuinely uncertain. But none of these constraints are permanent, and organizations that dismiss K2 entirely on the basis of origin may find themselves behind in a market that is moving faster than their procurement cycles.
The more defensible position is to evaluate K2 on its merits for specific workloads—particularly those involving self-hosted deployment, where the data sovereignty concerns largely dissolve—while keeping honest about the long-term risks of supply chain dependence on Chinese infrastructure. That is not a simple calculation, but the AI infrastructure decisions that matter rarely are.
What K2 has settled is the underlying question of whether frontier-quality long-context AI can be built outside the Silicon Valley–Seattle corridor. It can. Whether Moonshot can build the ecosystem to match the model—and whether Western enterprises will move quickly enough to find out—is what remains open.
Future Outlook
The trajectory of MoE architectures points toward increasingly specialized systems—models routing not between fixed expert sub-networks, but between dynamically loaded expert modules tuned for specific domains. Moonshot’s expertise in long-context training positions it well here; the engineering discipline required to train reliably on million-token sequences transfers directly to building highly specialized expert networks on deep domain corpora.
More broadly, the commoditization dynamic K2 accelerates is structural and won’t reverse. As open-weight models continue to close the capability gap with proprietary systems, value in the AI stack migrates away from raw model capabilities and toward data assets, fine-tuning infrastructure, and application-layer integration. The providers that sustain pricing power will be those with genuine ecosystem depth—not raw performance advantages, but integration into the workflows enterprise buyers depend on daily. OpenAI’s Microsoft relationship and Anthropic’s AWS position are structural moats. Benchmark scores are not.
That’s uncomfortable for providers whose primary value proposition is model quality. For enterprises, it means competitive frontier capabilities at costs that would have seemed implausible two years ago.
As AI becomes more accessible, organizations are increasingly focusing on practical deployment strategies and measurable business outcomes rather than benchmark scores alone. This trend is already visible across many of the best AI tools for small businesses entering the market.
Final Verdict
Kimi K2 makes a credible case that long-context AI doesn’t require a proprietary American cloud. For software engineers working with large codebases, organizations processing high-volume document corpora, and enterprises that value infrastructure control enough to run open weights on private hardware, K2 warrants a serious evaluation—not a proof-of-concept, but a genuine technical assessment against specific workloads.
It is not a substitute for Claude if you’re building polished, conversation-forward developer tooling. It is not a substitute for Gemini if real-time multimodal processing is central to your use case. It is not a substitute for GPT-4o if your organization is deeply embedded in the Microsoft ecosystem. But for the substantial share of enterprise AI use cases that don’t require any of those things—particularly those that require holding large volumes of structured text in active memory and reasoning across them—K2 is competitive with anything currently available, open or proprietary.
The ecosystem and compliance questions are real. They are, however, engineering and legal problems, not fundamental capability gaps. Moonshot AI has demonstrated it can build a frontier model. Whether it can build a frontier platform is what the next two years will answer.
| Model | Best For |
|---|---|
| Kimi K2 | Long-context reasoning |
| Claude | Coding & analysis |
| ChatGPT | Ecosystem & productivity |
| Gemini | Multimodal workflows |
FAQs
What is Kimi K2’s maximum context length?
Kimi K2 supports multi-million token context windows with retrieval accuracy that holds across its full supported length—a result of pre-training on long sequences rather than applying post-hoc extension techniques.
Can enterprises self-host Kimi K2?
Yes. Open-weight configurations are available for deployment via vLLM or TensorRT-LLM on private GPU infrastructure, including AWS, Azure, or on-premise clusters. For organizations with data sovereignty requirements, this is the recommended deployment path.
How does K2’s coding performance compare to Claude 3.5 Sonnet?
Claude 3.5 Sonnet is the stronger model for focused, localized code generation where clean syntax and architectural intent matter most. K2 is stronger at reasoning across large multi-file codebases as unified artifacts. For most teams, the right choice depends on the scale of the codebase, not the quality of the code.
Is Kimi K2 fully open-source?
No. K2 is open-weight: the model weights are publicly accessible for deployment, inspection, and fine-tuning. Training data and pre-training code remain proprietary—the same arrangement that applies to Meta’s LLaMA releases.
What are the primary cost advantages of the K2 API?
Moonshot has priced the K2 API well below Western frontier models on a per-million-token basis. For high-volume batch workloads, the total cost reduction is material. Self-hosted open-weight deployments eliminate variable token costs entirely, converting AI inference into a fixed infrastructure expense.
Does K2 support video and audio inputs?
K2 handles text and images with high accuracy. Native real-time audio and video streaming are not currently supported—a meaningful gap relative to Google’s Gemini.
What compliance risks should Western enterprises evaluate?
Organizations routing sensitive data through Moonshot’s API endpoints should assess cross-border data transfer regulations, China’s data security and national intelligence statutes, and relevant sector-specific frameworks (HIPAA, GDPR, FedRAMP). Self-hosted open-weight deployment keeps data within the organization’s own infrastructure and substantially mitigates these concerns.
How does K2 handle complex multi-step reasoning?
K2 allocates additional inference steps on complex queries to form hypotheses, verify internal consistency, and self-correct before generating output. This differs structurally from OpenAI’s o1 chain-of-thought (which runs inside a hidden reasoning trace), but produces comparable benefits for tasks that require careful logical verification.
Where can developers access Kimi K2?
Via Moonshot AI’s API platform, or through open-weight downloads on Hugging Face and ModelScope for self-hosted deployment.
